I'm processing XML documents like the following.
<tok lemma="i" xpos="CC">e</tok>
<tok lemma="que" xpos="CS">que</tok>
<tok lemma="aquey" xpos="PD0MP0">aqueys</tok>
<tok lemma="marit" xpos="NCMP000">marits</tok>
<tok lemma="estar" xpos="VMIP3P0">stiguen</tok>
[...]
<tok lemma="habitar" xpos="VMIP3P0">habiten</tok>
<tok lemma="en" xpos="SPS00">en</tok>
<tok lemma="aquex" xpos="PD0FS0">aqueix</tok>
<tok lemma="terra" xpos="NCMS000">món</tok>
[...]
<tok lemma="viure" xpos="VMIP3P0">viuen</tok>
<tok lemma="en" xpos="SPS00">en</tok>
<tok lemma="aquex" xpos="PD0FP0">aqueixes</tok>
<tok lemma="casa" xpos="NCFP000">cases</tok>
I need to change the attributes of certain elements whenever certain conditions are met. With the help of @LMC (see: 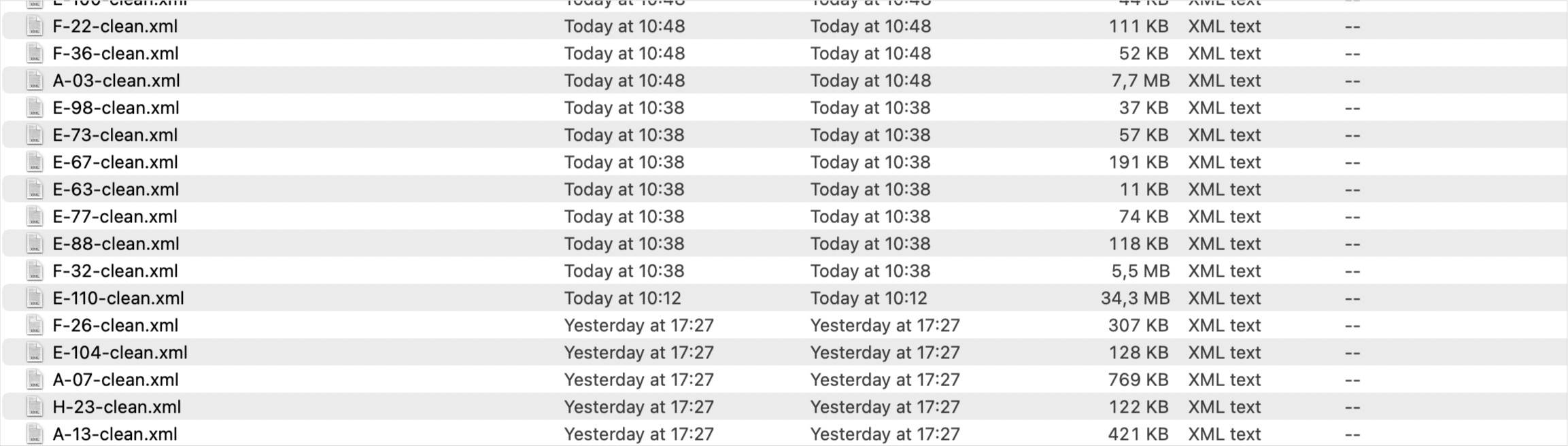
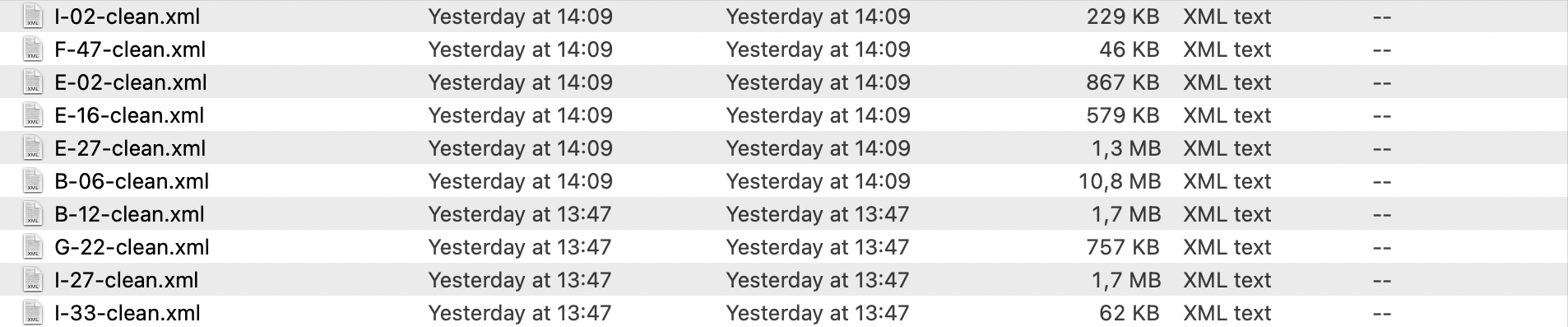
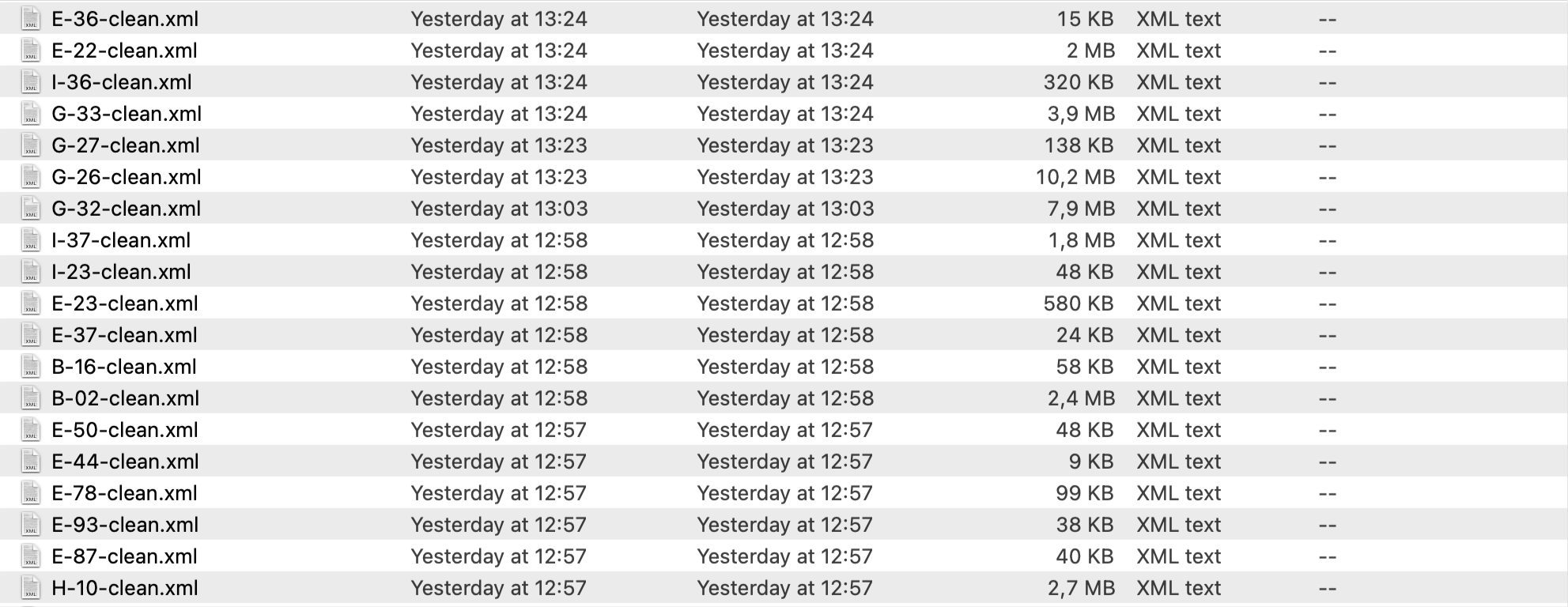
I cannot see much of a correlation between the size of the files and the times it takes to process them. At any rate, even if the file is large, it seems to me that 17 hours to process a single file is a bit too much. What do you think? Am I wrong and this is what should be expected with these kinds of jobs or there is something I'm doing wrong? Is there anything I could do to make this faster?
CodePudding user response:
There's something pathological going on here, there's no way it should take this long. Things I would try to isolate the cause:
(a) see if there is any network traffic generated.
(b) take a look at memory consumption to see if there's excessive paging or garbage collection
(c) reduce the processing you're doing on each document to something trivial to see if the problem is with parsing/saving the documents, or with the processing you are doing on each document.
UPDATE
Looking at the comments since I wrote this answer you seem to be making good progress in eliminating some possible causes and homing in on issues where a small change makes a big difference. It does look to me from reading the thread that you've got some XPath navigation with quadratic performance that's blowing up on large documents. I don't know the XPath processor you're using and it might well depend on fine details of exactly what it optimizes and what it doesn't. I find it surprising that this XPath expression should have non-linear performance. I'd be inclined to suggest trying it with SaxonC, which also has a Python API [disclaimer, that's my company's product].
CodePudding user response:
There might be a problem with variable naming since root variable has 2 meanings in the code which could cause a memory problem.
Given the example below
>>> t = os.walk('/home/lmc/tmp/a')
>>> for root, dirs, files in t:
... print(root)
... root= uuid.uuid4()
... print(root)
...
/home/lmc/tmp/a
ab5839a8-43b5-4d9d-bbb3-4836c612abaf
/home/lmc/tmp/a/b
7a8ba22e-7a02-45d6-82ce-538e11b70e7d
/home/lmc/tmp/a/b/c
de7c0e08-edc4-43e6-9bc1-9b1d7dd7e9db
/home/lmc/tmp/a/b/c/f
2536e2dc-11d1-4b41-86fd-128c3eeaddbc
/home/lmc/tmp/a/b/c/f/g
7d7e61b0-31d4-4af4-9097-540fc2bbac1c
/home/lmc/tmp/a/b/d
1a671eb2-7efe-4dc4-891b-94d1710ef638
/home/lmc/tmp/a/b/d/e
420d5228-44f1-493d-9dae-e2005c4e0f61
So instead of a directory name root might be holding an xml element on each instance of that list.
Removing withespace from parsed tree could also reduce the number of nodes in the tree
for root, dirs, files in os.walk(ROOT):
# iterate all files
for file in files:
if file.endswith(ext):
# join root dir and file name
file_path = os.path.join(ROOT, file)
# load root element from file
parser = etree.XMLParser(remove_blank_text=True)
root_ele = et.parse(file_path, parser).getroot()
# recursively change elements from xml
xml_change(root_ele)
Finally, as suggested, changing the xpath search strategy also makes a difference
for el in root.xpath('//tok[starts-with(@xpos, "N")]/preceding-sibling::tok[1]'):