I have the following dataframe:
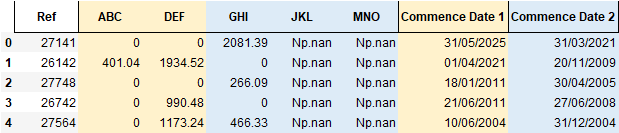
Code to recreate above:
input_lst = [[27141, 0, 0, 2081.39, np.nan, np.nan, '31/05/2025', '31/03/2021'],
[26142, 401.04, 1934.52, 0, np.nan, np.nan, '01/04/2021', '20/11/2009'],
[27748, 0, 0, 266.09, np.nan, np.nan, '18/01/2011', '30/04/2005'],
[26742, 0, 990.48, 0, np.nan, np.nan, '21/06/2011', '27/06/2008'],
[27564, 0, 1173.24, 466.33, np.nan, np.nan, '10/06/2004', '31/12/2004']]
input_headers = ['Ref', 'ABC', 'DEF', 'GHI', 'JKL', 'MNO', 'Commence Date 1', 'Commence Date 2']
test_df = pd.DataFrame(input_lst, columns=input_headers)
I want to reshape the dataframe or something similar, so my resulting dataframe looks like this:
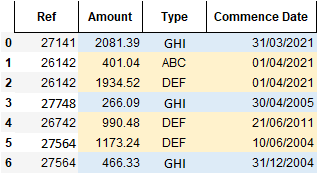
Code to view resulting dataframe:
res_lst = [[27141, 2081.39, 'GHI', '31/03/2021'],
[26142, 401.04, 'ABC', '01/04/2021'],
[26142, 1934.52, 'DEF', '01/04/2021'],
[27748, 266.09, 'GHI', '30/04/2005'],
[26742, 990.48, 'DEF', '21/06/2011'],
[27564, 1173.24, 'DEF', '10/06/2004'],
[27564, 466.33, 'GHI', '31/12/2004']]
res_headers = ['Ref', 'Amount', 'Type', 'Commence Date']
result_df = pd.DataFrame(res_lst, columns=res_headers)
For each 'Ref' row, there can be up to 5 columns (ABC, DEF, GHI, JKL, MNO) in the original dataframe. The figures held in those columns in the original dataframe will be output to a column called 'Amount', but the 'Type' column is essentially what is the corresponding header name for those amounts. These also need to have a 'Commence Date' based on a condition. If original 'Type' is in either what is held under ABC or DEF, the resulting dataframe should output what is in 'Commence Date 1', otherwise if it's GHI/JKL/MNO, it should use 'Commence Date 2'.
CodePudding user response:
Melt the dataframe with the required indices and values columns, then filter out the records with NaN, or 0 amount, then finally assign the Date values based on type:
out = test_df.melt(['Ref', 'Commence Date 1', 'Commence Date 2'],
['ABC', 'DEF', 'GHI', 'JKL', 'MNO'],
'Type',
'Amount')
out = out[~(pd.isna(out['Amount']) | out['Amount'].eq(0))]
out = (out.assign(**{
'Commence Date': out.apply(lambda x: x['Commence Date 1']
if x['Type'] in {'ABC', 'DEF'} else x['Commence Date 2'],
axis=1)})
.drop(columns=['Commence Date 1', 'Commence Date 2'])
)
OUTPUT
Ref Type Amount Commence Date
1 26142 ABC 401.04 01/04/2021
6 26142 DEF 1934.52 01/04/2021
8 26742 DEF 990.48 21/06/2011
9 27564 DEF 1173.24 10/06/2004
10 27141 GHI 2081.39 31/03/2021
12 27748 GHI 266.09 30/04/2005
14 27564 GHI 466.33 31/12/2004
You can reset the index of resulting dataframe, sort the dataframe on Ref column based on your preferences.
CodePudding user response:
melt is a good option; however, it might not be efficient, depending on the data size - you have rows that are 0 or nan, which you do not care about; melt returns all those rows, after which you then filter. A better option would be to avoid flipping to long form, and avoid the nulls. It is a longer process, but should be beneficial as the data size increases.
# select the columns from ABC to MNO
arr = test_df.loc[:, 'ABC':'MNO']
# get the columns, we'll use that later
arr_cols = arr.columns
# get boolean output for rows greater than 0
arr = arr.to_numpy()
bools = arr > 0
# get row and col positions for True values
row, col = bools.nonzero()
# create the Ref series
ref = test_df.Ref.repeat(bools.sum(1))
ref.index = range(len(ref))
# get the Type series
types = arr_cols[col]
types = pd.Series(types, name = 'Type')
# get the Amount
amount = arr[row, col]
amount = pd.Series(amount, name = 'Amount')
# Extract the dates
dates = test_df.filter(like='Comm').to_numpy()
# generate index, we'll use the index
# in combination with `row` to get the matching dates
# ABC, DEF are 0 and 1
# hence the conditional below
ind = np.where(col < 2, 0, 1)
dates = dates[row, ind]
dates = pd.Series(dates, name = 'Commence Date')
# combine ref, types, amount, dates
out = pd.concat([ref, types, amount, dates], axis = 1)
out
Ref Type Amount Commence Date
0 27141 GHI 2081.39 31/03/2021
1 26142 ABC 401.04 01/04/2021
2 26142 DEF 1934.52 01/04/2021
3 27748 GHI 266.09 30/04/2005
4 26742 DEF 990.48 21/06/2011
5 27564 DEF 1173.24 10/06/2004
6 27564 GHI 466.33 31/12/2004
Again, you'd bother with this long process if you are looking for efficiency, otherwise the melt solution above does the job.