Given a dict like this:
d={'paris':['a','b'],
'brussels':['b','c'],
'mallorca':['a','d']}
#when doing:
df = pd.DataFrame(d)
df.T
I dont get the expected result. What I would like to get is a one_hot_encoding DF, in which the columns are the capitals and the value 1 or 0 corresponds to every of the letters that every city includes being paris, mallorca ect
The desired result is:
df = pd.DataFrame([[1,1,0,0],[0,1,1,0],[1,0,0,1]], index=['paris','brussels','mallorca'], columns=list('abcd'))
df.T
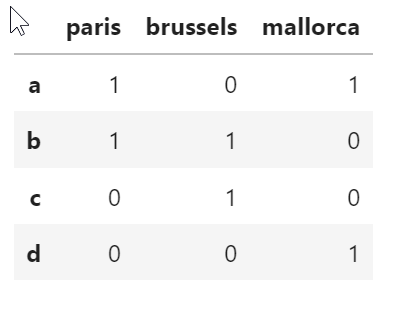
Any clever way to do this without having to multiloop over the first dict to transform it into another one?
CodePudding user response:
Solution 1:
- Combine
df.applywithseries.value_countsand appenddf.fillnato fillNaNvalues with zeros.
out = df.apply(pd.Series.value_counts).fillna(0)
print(out)
paris brussels mallorca
a 1.0 0.0 1.0
b 1.0 1.0 0.0
c 0.0 1.0 0.0
d 0.0 0.0 1.0
Solution 1:
- Transform your
dfusingdf.meltand then use the result insidepd.crosstab. - Again use
df.fillnato changeNaNvalues to zeros. Finally, reorder the columns based on the order in the originaldf.
out = df.melt(value_name='index')
out = pd.crosstab(index=out['index'], columns=out['variable'])\
.fillna(0).loc[:, df.columns]
print(out)
paris brussels mallorca
index
a 1 0 1
b 1 1 0
c 0 1 0
d 0 0 1
CodePudding user response:
I don't know how 'clever' my solution is but it works and it is pretty consise and readable.
import pandas as pd
d = {'paris': ['a', 'b'],
'brussels': ['b', 'c'],
'mallorca': ['a', 'd']}
df = pd.DataFrame(d).T
df.columns = ['0', '1']
df = pd.concat([df['0'], df['1']])
df = pd.crosstab(df, columns=df.index)
print(df)
Yields:
brussels mallorca paris
a 0 1 1
b 1 0 1
c 1 0 0
d 0 1 0