I have Selenium opening many pdfs for me from Google Search (using f"https://www.google.com/search?q=filetype:pdf {search_term}" and then clicking on the first link)
I want to know which pages contain my keyword WITHOUT downloading the pdf first. I believe I can use
Ctrl F --> keyword --> {scrape page number} --> Tab (next keyword) --> {scrape page number} --> ... --> switch to next PDF
How can I accomplish the {scrape page number} part?
Context
For each PDF I need to grab these numbers as a list or in a Pandas DataFrame or anything I can use to feed in camelot.read_pdf() later
The idea is also once I have these page numbers, I can selectively download pages of these pdfs and save on storage, memory and network speeds rather than downloading and parsing the entire pdf
Using BeautifulSoup
PDFs have a small gray box at the top with the current page number and total pages number with the option to skip around the PDF.
<input data-element-focusable="true" id="pageselector" type="text" value="151" title="Page number (Ctrl Alt G)" aria-label="Go to any page between 1 and 216">
The value in this input tag contains the number I am looking for.
Other SO answers
I'm aware that reading PDFs programatically is challenging and I'm currently using this function (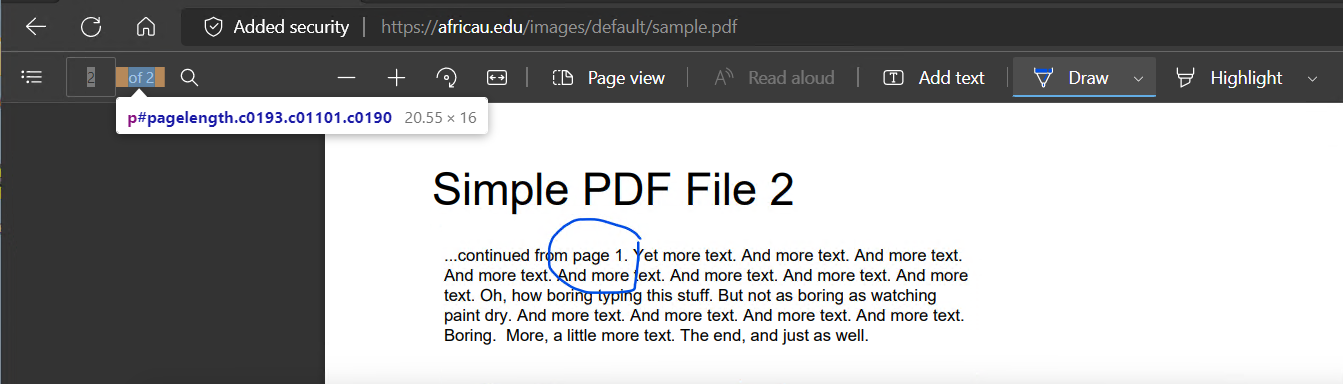
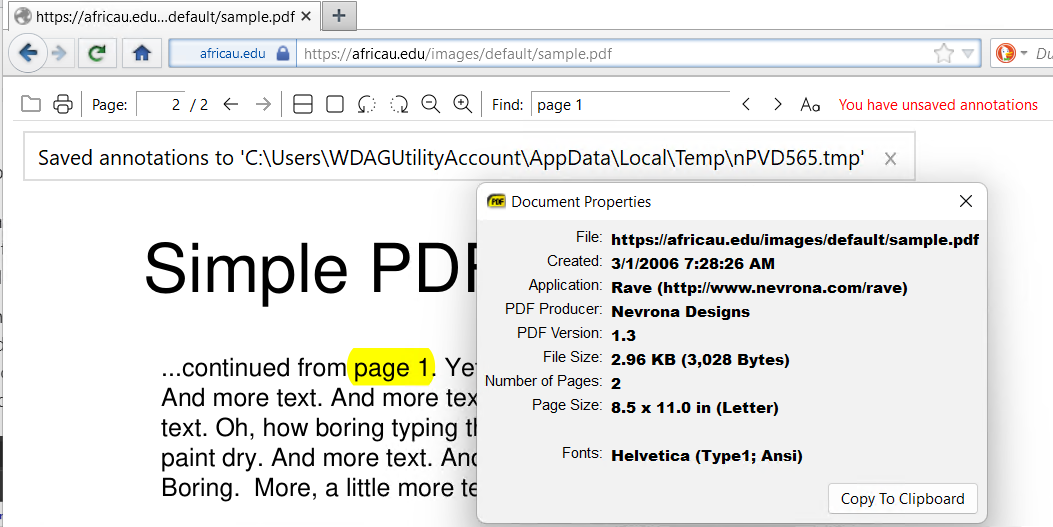
It does not matter which browser extension you are using they all hold the file somewhere in your file system, note the difference here the data says its on the web but the edit message show otherwise. In this case the field is secured outside the browser however Ctrl D C gives me
File: https://africau.edu/images/default/sample.pdf
Created: 3/1/2006 7:28:26 AM
Application: Rave (http://www.nevrona.com/rave)
PDF Producer: Nevrona Designs
PDF Version: 1.3
File Size: 2.96 KB (3,028 Bytes)
Number of Pages: 2
Page Size: 8.5 x 11.0 in (Letter)
Fonts: Helvetica (Type1; Ansi)
Mozilla PDF.js is a different beast, so may be more addressable, but as you found you can use a hybrid approach in the index.htm of Chrome/Edge you could equally do that offline.
So on the basis you have scraped a list of URLs the simplest solution should be
curl -O (or -o tmp.pdf) URL & pdftotext | find "Keyword"
you will need to adapt that a bit to show page and line number but that's a different question or two
https://stackoverflow.com/a/72440765/10802527
https://stackoverflow.com/a/72778117/10802527