I have a stored procedure that is running unusually long.... Narrowing down. I got the below...
Long running query:
select @TimeStamp = getdate()
select @TimeStamp
Use FSFruit;
select *,
case when @intDaysToGrowInQ1 = 0 then 0 else (me1) end yme1,
case when @intDaysToGrowInQ2 = 0 then 0 else (me1 me2) end yme2,
case when @intDaysToGrowInQ3 = 0 then 0 else (me1 me2 me3) end yme3,
case when @intDaysToGrowInQ4 = 0 then 0 else (me1 me2 me3 me4) end yme4
into #temp1
from mq_fruit
where fruit_suffix **in** ('A1', 'O1', 'S1') **OR**
balance_type **in** (select fruit_type from REF.dbo.fruit_type_tbl where fruit_type_group = 'TOT')
select @TimeStamp = getdate()
select @TimeStamp
total time it took is around 25 mins. (9095000 rows affected)
there is another almost similar query that runs faster
select @TimeStamp = getdate()
select @TimeStamp
Use FSFruit;
select *,
case when @intDaysToGrowInQ1 = 0 then 0 else (me1) end yme1,
case when @intDaysToGrowInQ2 = 0 then 0 else (me1 me2) end yme2,
case when @intDaysToGrowInQ3 = 0 then 0 else (me1 me2 me3) end yme3,
case when @intDaysToGrowInQ4 = 0 then 0 else (me1 me2 me3 me4) end yme4
into #temp1
from mq_fruit
where fruit_suffix **not in** ('A1', 'O1', 'S1') **and**
fruit_type **not in** (select fruit_type from REF.dbo.fruit_type_tbl where fruit_type_group = 'TOT')
select @TimeStamp = getdate()
select @TimeStamp
total time it took is around 3 mins. (7080000 rows affected)
Trying to figure out why the difference. The first runs longer the second runs faster.
mq_fruit and fruit_type_tbl do not have any indexes.
What I am missing to make the first query faster in execution.
Thanks.
Updated:
actual exec plan
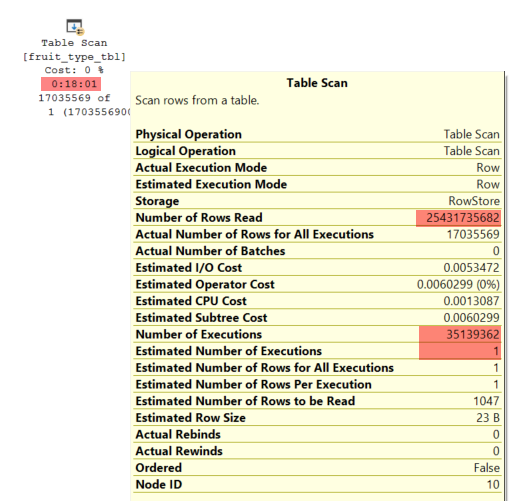
The following will likely be a massive improvement as it will only scan it once.
SELECT *
FROM (SELECT DISTINCT fruit_type
FROM dbo.fruit_type_tbl
WHERE fruit_type_group = 'TOT') ft
RIGHT HASH JOIN mq_fruit mq
ON ft.fruit_type = mq.fruit_type
WHERE mq.fruit_suffix IN ( 'A1', 'O1', 'S1' )
OR ft.fruit_type IS NOT NULL
The query is never going to be that fast though as 17 million of the 35 million rows in mq_fruit do in fact meet one or the other condition so you are returning a lot of data to the client (especially with *).
The estimated row size is 362 bytes so that would be > 6GB if accurate. Your current query does have 108 seconds of ASYNC_NETWORK_IO waits that likely are largely attributable to this.
(I haven't bothered suggesting any indexing as fruit_type_tbl is small anyway and will only be scanned once and the large percentage of rows actually required from mq_fruit along with use of * and use of or means there is not a clear candidate index on that side.)