I'm having trouble using python multiprocess.
im trying with a minimal version of code:
import os
os.environ["OMP_NUM_THREADS"] = "1" # just in case the system uses multithrad somehow
os.environ["OPENBLAS_NUM_THREADS"] = "1" # just in case the system uses multithrad somehow
os.environ["MKL_NUM_THREADS"] = "1" # just in case the system uses multithrad somehow
os.environ["VECLIB_MAXIMUM_THREADS"] = "1" # just in case the system uses multithrad somehow
os.environ["NUMEXPR_NUM_THREADS"] = "1" # just in case the system uses multithrad somehow
import numpy as np
from datetime import datetime as dt
from multiprocessing import Pool
from pandas import DataFrame as DF
def trytrytryshare(times):
i = 0
for j in range(times):
i =1
return
def trymultishare(thread = 70 , times = 10):
st = dt.now()
args_l = [(times,) for i in range(thread)]
print(st)
p = Pool(thread)
for i in range(len(args_l)):
p.apply_async(func = trytrytryshare, args = (args_l[i]))
p.close()
p.join()
timecost = (dt.now()-st).total_seconds()
print('%d threads finished in %f secs' %(thread,timecost))
return timecost
if __name__ == '__main__':
res = DF(columns = ['thread','timecost'])
n = 0
for j in range(5):
for i in range(1,8,3):
timecost = trymultishare(thread = i,times = int(1e8))
res.loc[n] = [i,timecost]
n =1
timecost = trymultishare(thread = 70,times = int(1e8))
res.loc[n] = [70,timecost]
n =1
res_sum = res.groupby('thread').mean()
res_sum['decay'] = res_sum.loc[1,'timecost'] / res_sum['timecost']
on my own computer (8cores):
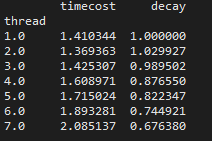
on my server (80 cores, im the only one using it)
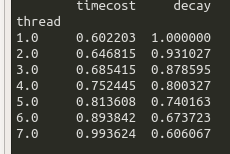
i tried again, make one thread job longer.
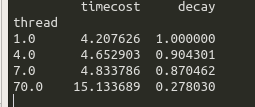
the decay is really bad....
any idea how to "fix" this, or this is just what i can get when using multi-process?
thanks
CodePudding user response:
The way you're timing apply_async is flawed. You won't know when the subprocesses have completed unless you wait for their results.
It's a good idea to work out an optimum process pool size based on number of CPUs. The code that follows isn't necessarily the best for all cases but it's what I use.
You shouldn't set the pool size to the number of processes you intend to run. That's the whole point of using a pool.
So here's a simpler example of how you could test subprocess performance.
from multiprocessing import Pool
from time import perf_counter
from os import cpu_count
def process(n):
r = 0
for _ in range(n):
r = 1
return r
POOL = max(cpu_count()-2, 1)
N = 1_000_000
def main(procs):
# no need for pool size to be bigger than the numer of processes to be run
poolsize = min(POOL, procs)
with Pool(poolsize) as pool:
_start = perf_counter()
for result in [pool.apply_async(process, (N,)) for _ in range(procs)]:
result.wait() # wait for async processes to terminate
_end = perf_counter()
print(f'Duration for {procs} processes with pool size of {poolsize} = {_end-_start:.2f}s')
if __name__ == '__main__':
print(f'CPU count = {cpu_count()}')
for procs in range(10, 101, 10):
main(procs)
Output:
CPU count = 20
Duration for 10 processes with pool size of 10 = 0.12s
Duration for 20 processes with pool size of 18 = 0.19s
Duration for 30 processes with pool size of 18 = 0.18s
Duration for 40 processes with pool size of 18 = 0.28s
Duration for 50 processes with pool size of 18 = 0.30s
Duration for 60 processes with pool size of 18 = 0.39s
Duration for 70 processes with pool size of 18 = 0.42s
Duration for 80 processes with pool size of 18 = 0.45s
Duration for 90 processes with pool size of 18 = 0.54s
Duration for 100 processes with pool size of 18 = 0.59s
CodePudding user response:
My guess is that you're observing the cost of spawning new processes, since apply_async returns immediately. It's much cheaper to spawn one process in the case of thread==1 instead of spawning 70 processes (your last case with the worst decay).
The fact that the server with 80 cores performs better than you laptop with 8 cores could be due to the server containing better hardware in general (better heat removal, faster CPU, etc) or it might contain a different OS. Benchmarking across different machines is non-trivial.