| Source | Target |
|---|---|
 |
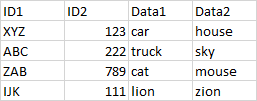 |
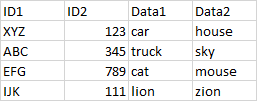
Two tables will be joined via composite keys ID1 and ID2 via pandas merge. We have a data testing tool that does the data analysis. It will perform the merge and filter whatever rows are not present on the left or right side of the merge into an external Missing In Source or Missing in Target table.
| Missing in Target | Missing in Source |
|---|---|
 |
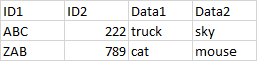 |
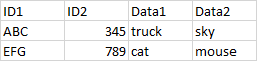
In this example in Source the second row with composite key ABC,345 is missing in Target. So that row will be filtered into Missing in Target. Similarly in Target the second row with composite key ABC,222 is missing in Source so it will be filtered into Missing in Source.
For the Missing ... tables the business wants to know "why exactly are they missing"--which composite key by row made the row missing? For example, for the row with ABC,345 in the Missing in Target above, ABC was present in both table rows but 345 wasn't. Therefore,ID2 with value 345 is the guilty key for this row.
CodePudding user response:
Try this using merge with how=outer and indicator:
import pandas as pd
df1 = pd.DataFrame({'ID1':'XYZ ABC EFG UK'.split(' '),
'ID2': [123,345, 789, 111],
'Data1':'car truck cat lion'.split(' '),
'Data2':'house sky mouse zion'.split(' ')})
df2 = pd.DataFrame({'ID1':'XYZ ABC ZAB UK'.split(' '),
'ID2':[123,222,789,111],
'Data1':'car truck cat lion'.split(' '),
'Data2':'house sky mouse zion'.split(' ')})
df_r = df1.merge(df2, how='outer', indicator='Ind')
df_source_missing = df_r.query('Ind == "left_only"')
df_target_missing = df_r.query('Ind == "right_only"')
Output:
print(df_source_missing)
ID1 ID2 Data1 Data2 Ind
1 ABC 345 truck sky left_only
2 EFG 789 cat mouse left_only
print(df_target_missing)
ID1 ID2 Data1 Data2 Ind
4 ABC 222 truck sky right_only
5 ZAB 789 cat mouse right_only
CodePudding user response:
I believe you want .compare:
import pandas as pd
data1 = {
"ID1": ["XYZ", "ABC", "EFG", "IJK"],
"ID2": [123, 345, 789, 111],
"DATA1": ["car", "truck", "cat", "lion"],
"DATA2": ["house", "sky", "mouse", "zion"]
}
data2 = {
"ID1": ["XYZ", "ABC", "ZAB", "IJK"],
"ID2": [123, 222, 789, 111],
"DATA1": ["car", "truck", "cat", "lion"],
"DATA2": ["house", "sky", "mouse", "zion"]
}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
df = (
df1
.compare(df2, align_axis=0)
.rename(index={"self": "df1", "other": "df2"}, level=-1)
.fillna("")
.reset_index()
.drop("level_0", axis=1)
.rename(columns={"level_1": "source"})
)
print(df)
source ID1 ID2
0 df1 345.0
1 df2 222.0
2 df1 EFG
3 df2 ZAB