I have data as shown in the picture, please check the dataframe here:
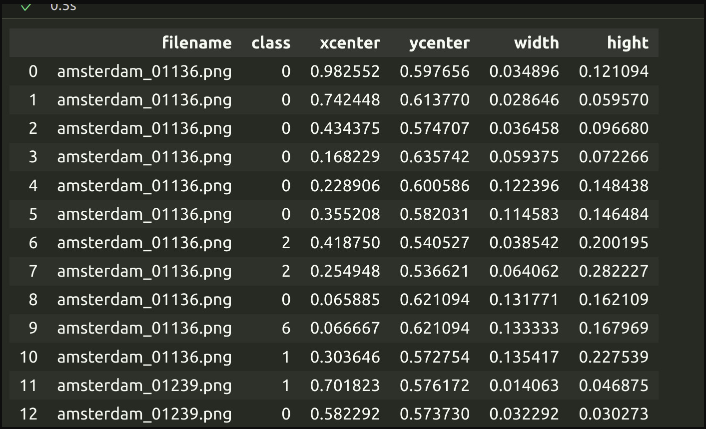
I want to convert that data amsterdam_01136.txt, amsterdam_01239.txt ... so on
which should look like this (yolo object detection annotation format)
0 0.982552 0.597656 0.034896 0.121094
0 0.742448 0.613770 0.028646 0.059570
2 0.418750 0.540527 0.038542 0.200195
I tried using for loop as given here (3rd solution) link but it only adds the last row of the file name. please give me a suggestion
CodePudding user response:
df.to_csv(r'destination_path',sep=',',columns=[list of columns],index=False)
CodePudding user response:
Assuming your dataframe is this:
import pandas as pd
df = pd.DataFrame({'filename': ['amsterdam_01136.png', 'amsterdam_01136.png', 'amsterdam_01136.png'],
'class': [0,0,0],
'xcenter': [0.982,0.742,0.434],
'ycenter': [0.597,0.613,0.574],
'width': [0.034,0.028,0.036],
'height': [0.121,0.059,0.096] })
print(df)
filename class xcenter ycenter width height
0 amsterdam_01136.png 0 0.982 0.597 0.034 0.121
1 amsterdam_01136.png 0 0.742 0.613 0.028 0.059
2 amsterdam_01136.png 0 0.434 0.574 0.036 0.096
What would you like to do with repeated filenames for the first 11 rows?
for col in df.columns:
df[col] = df[col].astype('string')
for i in range(len(df)):
filename = df.iloc[i, 0].rsplit('.', 1)[0] '.txt'
print(filename)
line = ' '.join(df.iloc[i, 1:].tolist())
print(line)
with open(filename, 'w') as f:
f.write(line)
amsterdam_01136.txt
0 0.982 0.597 0.034 0.121
amsterdam_01136.txt
0 0.742 0.613 0.028 0.059
amsterdam_01136.txt
0 0.434 0.574 0.036 0.096