I have a pandas dataframe(after pivoted) which i am trying to save the file as parquet and store it in azure blob storage . The file is getting stored in the storage account, however when i try to read the parquet file, i am getting the error - "encoding RLE_DICTIONARY is not supported." Can some one help me how to fix this.
Here is the below code which i am using for saving the dataframe.
blob_service_client = BlobServiceClient.from_connection_string(<<connectionstring>>)
blob_client = blob_service_client.get_blob_client(container='<<container Name>>', blob="department/abc.parquet")
parquet_file = BytesIO()
df.to_parquet(parquet_file,engine='pyarrow',index=False)
parquet_file.seek(0)
blob_client.upload_blob(data=parquet_file)
CodePudding user response:
After reproducing from my end, I could able to make this work by uploading Iterable data using upload_blob. In my case I'm iterating over the Bytes of the file. Below is the code that worked for me.
from azure.storage.blob import BlobServiceClient
import pandas as pd
storage_account_name='<STORAGE_ACCOUNT_NAME>'
storage_account_key='<STORAGE_ACCOUNT_KEY>'
container_name='<CONTAINER_NAME>'
service_client = BlobServiceClient(account_url="{}://{}.blob.core.windows.net/".format("https",storage_account_name), credential=storage_account_key)
container_client = service_client.get_container_client(container=container_name)
file = open("userdata5.parquet", "rb")
data = file.read()
file_client = container_client.upload_blob(name="abc.parquet",data=data)
file.close
print("Done Uploading")
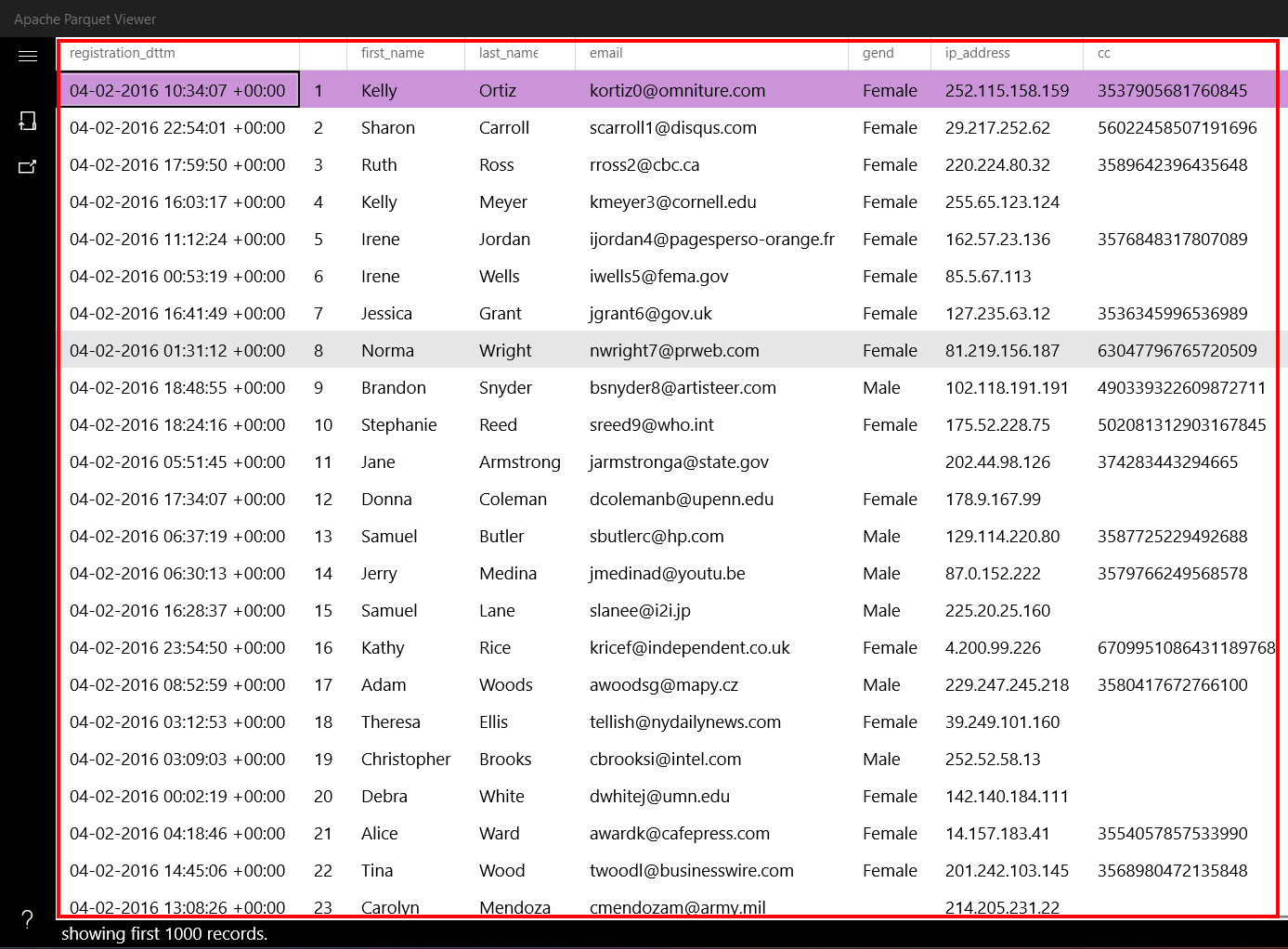
RESULTS:
abc.parquet
CodePudding user response:
I was able to fix this issue by adding this code. df.to_parquet(parquet_file,engine='pyarrow',index=False,use_dictionary=False)