I have the following pandas DataFrame:
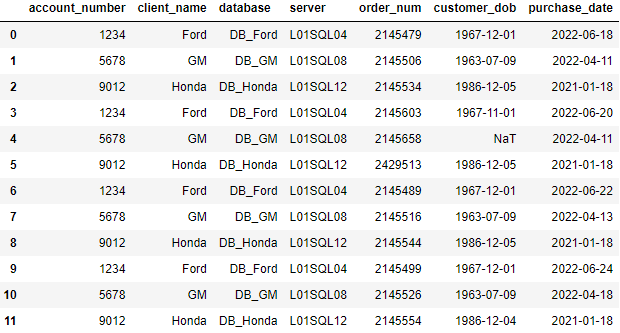
account_number = [1234, 5678, 9012, 1234.0, 5678, 9012, 1234.0, 5678, 9012, 1234.0, 5678, 9012]
client_name = ["Ford", "GM", "Honda", "Ford", "GM", "Honda", "Ford", "GM", "Honda", "Ford", "GM", "Honda"]
database = ["DB_Ford", "DB_GM", "DB_Honda", "DB_Ford", "DB_GM", "DB_Honda", "DB_Ford", "DB_GM", "DB_Honda", "DB_Ford", "DB_GM", "DB_Honda"]
server = ["L01SQL04", "L01SQL08", "L01SQL12", "L01SQL04", "L01SQL08", "L01SQL12", "L01SQL04", "L01SQL08", "L01SQL12", "L01SQL04", "L01SQL08", "L01SQL12"]
order_num = [2145479, 2145506, 2145534, 2145603, 2145658, 2429513, 2145489, 2145516, 2145544, 2145499, 2145526, 2145554]
customer_dob = ["1967-12-01", "1963-07-09", "1986-12-05", "1967-11-01", None, "1986-12-05", "1967-12-01", "1963-07-09", "1986-12-05", "1967-12-01", "1963-07-09", "1986-12-04"]
purchase_date = ["2022-06-18", "2022-04-11", "2021-01-18", "2022-06-20", "2022-04-11", "2021-01-18", "2022-06-22", "2022-04-13", "2021-01-18", "2022-06-24", "2022-04-18", "2021-01-18"]
d = {
"account_number": account_number,
"client_name" : client_name,
"database" : database,
"server" : server,
"order_num" : order_num,
"customer_dob" : customer_dob,
"purchase_date" : purchase_date,
}
df = pd.DataFrame(data=d)
dates = ["customer_dob", "purchase_date"]
for date in dates:
df[date] = pd.to_datetime(df[date])
The customer's date of birth (DOB) and purchase date (PD) should be the same per account_number, but since there can be a data entry error on either one, I want to perform a groupby on the account_number and get the max on the DOB, and the min on the PD. This is easy to do if all I want are those two columns in addition to the account_number:
result = df.groupby("account_number").agg({"customer_dob": "max", "purchase_date": "min"}).reset_index()
result
However, I want the other columns as well, as they are guaranteed to be the same for each account_number. The problem is, when I attempt to include the other columns, I get multi-level columns, which I don't want. This first attempt not only produced multi-level columns, but I don't even see the actual values for DOB and PD

result = df.groupby("account_number")["client_name", "database", "server", "order_num"].agg({"customer_dob": "max", "purchase_date": "min"}).reset_index()
result
The second attempt included the DOB and PD, but now twice for each account number, while still producing multi-level columns:

result = df.groupby("account_number")["client_name", "database", "server", "order_num", "customer_dob", "purchase_date"].agg(
{"patient_dob": "max", "insert_date": "min"}).reset_index()
result
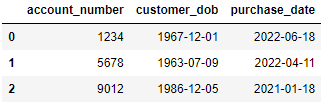
I just want the end result to look like this:

So, that's my question to all you Python experts: what do I need to do to accomplish this?
CodePudding user response:
leaving the order number out, per your comment above. If order # are same for an account, then add the order number to the columns list in merge
result = df.groupby("account_number").agg({"customer_dob": "max", "purchase_date": "min"}).reset_index()
result.merge(df[['account_number','client_name','database','server' ]] ,
how='left',
on='account_number').drop_duplicates()
account_number customer_dob purchase_date client_name database server
0 1234.0 1967-12-01 2022-06-18 Ford DB_Ford L01SQL04
4 5678.0 1963-07-09 2022-04-11 GM DB_GM L01SQL08
8 9012.0 1986-12-05 2021-01-18 Honda DB_Honda L01SQL12
CodePudding user response:
You can use:
agg(new_col_1=(col_1, 'sum'), new_col_2=(col_2, 'min'))