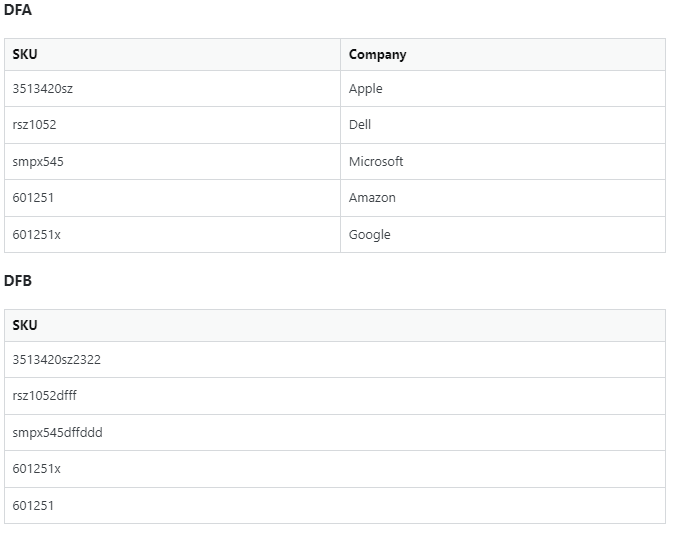
I have 2 DFs DFA & DFB
What I want to do is find a match between a string or a substring on the SKU column and merge the Company column to DFB
Code
// Remove white spaces, special characters and convert d type to string
dfa['Clean SKU'] = dfa['SKU'].replace(r'[^0-9a-zA-Z ]', '', regex=True).replace("'", '')
dfb['Clean SKU'] = dfb['SKU'].replace(r'[^0-9a-zA-Z ]', '', regex=True).replace("'", '')
dfa['Clean SKU'] = dfa['Clean SKU'].replace(r'\s ', '', regex=True)
dfb['Clean SKU'] = dfb['Clean SKU'].replace(r'\s ', '', regex=True)
# Change D.Types
dfa['Clean SKU'] = dfa['Clean SKU'].astype(str)
dfb['Clean SKU'] = dfb['Clean SKU'].astype(str)
// Create new column to merge on and convert to lowercase
dfa['SKU_to_merge'] = dfa['Clean SKU'].str.lower()
// Extract a unique list from the Clean SKU column
pat = r'(%s)'%'|'.join(dfa['Clean SKU'].str.lower().unique())
// Create a column with common matches
dfb['SKU_to_merge'] = dfb['Clean SKU'].str.lower().str.extract(pat)
// Merge the DFs on the SKU to merge
dfb = dfb.merge(dfa[['SKU_to_merge','Company']], on='SKU_to_merge', how='left')
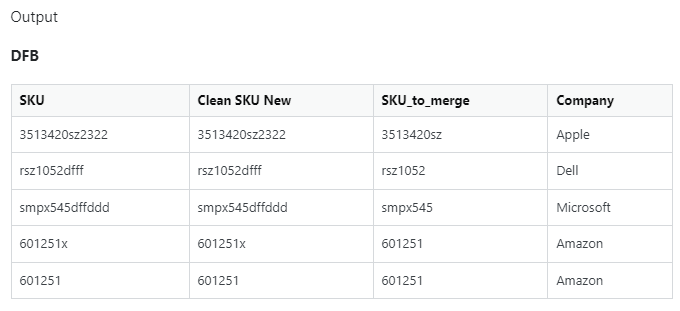
ISSUE For SKU 601251x the SKU_to_merge should be 601251x as this SKU is in DFA (should only match by substring where direct matching is not possible). So in this instance the corresponding Company should be Google not Amazon
CodePudding user response:
I'll skip the cleaning part, and assume the following state of the dfs (before you start building pat):
dfa:
SKU Company Clean SKU SKU_to_merge
0 3513420sz Apple 3513420sz 3513420sz
1 rsz1052 Dell rsz1052 rsz1052
2 smpx545 Microsoft smpx545 smpx545
3 601251 Amazon 601251 601251
4 601251x Google 601251x 601251x
dfb:
SKU Clean SKU
0 3513420sz2322 3513420sz2322
1 rsz1052dfff rsz1052dfff
2 smpx545dffddd smpx545dffddd
3 601251x 601251x
4 601251 601251
Then you could try
pat = '(' '|'.join(sorted(set(dfa['Clean SKU'].str.lower()), key=len, reverse=True)) ')'
dfb['SKU_to_merge'] = dfb['Clean SKU'].str.lower().str.extract(pat)
dfb = dfb.merge(dfa[['SKU_to_merge','Company']], on='SKU_to_merge', how='left')
and should get the following dfb:
SKU Clean SKU SKU_to_merge Company
0 3513420sz2322 3513420sz2322 3513420sz Apple
1 rsz1052dfff rsz1052dfff rsz1052 Dell
2 smpx545dffddd smpx545dffddd smpx545 Microsoft
3 601251x 601251x 601251x Google
4 601251 601251 601251 Amazon
The idea is to sort the parts of pat such that longer ones come first.
CodePudding user response:
Similar Problem Solution
https://towardsdatascience.com/joining-dataframes-by-substring-match-with-python-pandas-8fcde5b03933
import pandas as pd
df1 = pd.DataFrame([
['ABC', 'P1']
, ['BCD', 'P2']
, ['CDE', 'P3']
]
,columns = ['task_name', 'pipeline_name']
)
df2 = pd.DataFrame([
['RR', 'C1']
, ['BC', 'C2']
, ['HG', 'C3']
, ['AB', 'C4']
]
,columns = ['partial_task_name', 'extra_value']
)
df1['join'] = 1
df2['join'] = 1
dfFull = df1.merge(df2, on='join').drop('join', axis=1)
df2.drop('join', axis=1, inplace=True)
dfFull['match'] = dfFull.apply(lambda x: x.task_name.find(x.partial_task_name), axis=1).ge(0)
dfResult = dfFull.groupby(["task_name", "pipeline_name"]).max().reset_index()[['task_name','pipeline_name','match']]
dfResult[~dfResult['match']][['task_name','pipeline_name']]