part|24|vendor|0C|year|02|orgid|0E|date|03|tag|64
def0cdf7-e1bb-40fb-baf0-37e0c45b0cac30303039363321FR423808711364296Progressive uniform circuit
3e813cae-4f44-44ac-85b9-fa67c622791230303038303321SI235522319644338Multi-lateral eco-centric contingency
cd2128df-2336-427e-9ab7-94c2e6f6f23330303038313221MU34NYRU039046346Enterprise-wide impactful encoding
9580b7a1-b66b-48fb-9b22-385edb494abc30303037333321FR482592279169087Upgradable bi-directional implementation
27c31e43-0bf4-4220-ab88-e7643f3c6aa430303032373921AE853769731996032Realigned web-enabled hardware
01a32274-50bf-4a74-93ff-841cb70aeab030303035353721AE285621632570102Quality-focused 5th generation productivity
1491e670-5ecd-45c5-b85b-4f3273b4084930303034343321HU304042484774357Expanded asynchronous help-desk
5bb78560-51ca-4b86-b9fc-81d9610ab6c230303031333821BE429904898168225Visionary bi-directional paradigm
03718e50-5592-422d-b093-d7eaa7b69c6c30303039303121PL290819609662037Optimized 6th generation internet solution
826fefce-2730-4f4e-aeb4-39a9b0c4455030303034333621SM94M589367740206Persevering bottom-line core
80070dfe-9bc2-40cc-9458-46f04a30df0c30303037353721LB104536QN2PGL041Enhanced bifurcated service-deskI have searched it everywhere but I didn't find it.
Header seems like pipe delimited. But the data within the file is not separated by the pipes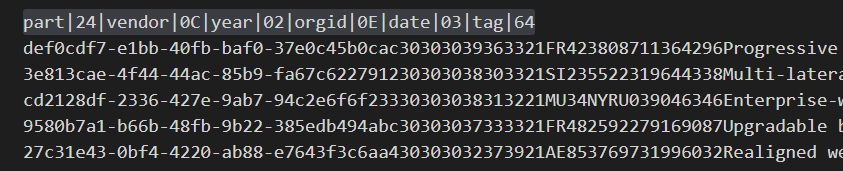 part|24|vendor|0C|year|02|orgid|0E|date|03|tag|64
part|24|vendor|0C|year|02|orgid|0E|date|03|tag|64
CodePudding user response:
Vishal it's not clear what you're trying to do. It is important to ask a clear question so people can help you.
You are correct that the data appears to have two different formats. The header is delimited by "|" (pipes), and the rows below it aren't delimited by anything.
This is probably not a question that people can help you with here. It relates to the cleaning of data. You will need to find the original data, or work with the people who created the data to clean it.
CodePudding user response:
The header is giving you the fixed width field lengths of the rows below. Each length is encoding in hex. The data rows do not have separators at all.
You need to first read the header in and convert each hex entry into an integer. It is then possible to read each line and slice it according to the lengths of each field.
This could be done as follows:
import csv
with open('input.csv') as f_input, open('output.csv', 'w', newline='') as f_output:
header = next(f_input).strip().split('|')
fields = [(field, int(length, 16)) for field, length in (zip(*[iter(header)] * 2))]
csv_output = csv.DictWriter(f_output, fieldnames=[field for field, length in fields])
csv_output.writeheader()
for line in f_input:
line = line.strip()
row = {}
offset = 0
for field, length in fields:
row[field] = line[offset : offset length]
offset = length
csv_output.writerow(row)
Giving a converted CSV output file as:
part,vendor,year,orgid,date,tag
def0cdf7-e1bb-40fb-baf0-37e0c45b0cac,303030393633,21,FR423808711364,296,Progressive uniform circuit
3e813cae-4f44-44ac-85b9-fa67c6227912,303030383033,21,SI235522319644,338,Multi-lateral eco-centric contingency
cd2128df-2336-427e-9ab7-94c2e6f6f233,303030383132,21,MU34NYRU039046,346,Enterprise-wide impactful encoding
9580b7a1-b66b-48fb-9b22-385edb494abc,303030373333,21,FR482592279169,087,Upgradable bi-directional implementation
27c31e43-0bf4-4220-ab88-e7643f3c6aa4,303030323739,21,AE853769731996,032,Realigned web-enabled hardware
01a32274-50bf-4a74-93ff-841cb70aeab0,303030353537,21,AE285621632570,102,Quality-focused 5th generation productivity
1491e670-5ecd-45c5-b85b-4f3273b40849,303030343433,21,HU304042484774,357,Expanded asynchronous help-desk
5bb78560-51ca-4b86-b9fc-81d9610ab6c2,303030313338,21,BE429904898168,225,Visionary bi-directional paradigm
03718e50-5592-422d-b093-d7eaa7b69c6c,303030393031,21,PL290819609662,037,Optimized 6th generation internet solution
826fefce-2730-4f4e-aeb4-39a9b0c44550,303030343336,21,SM94M589367740,206,Persevering bottom-line core
80070dfe-9bc2-40cc-9458-46f04a30df0c,303030373537,21,LB104536QN2PGL,041,Enhanced bifurcated service-desk