I am learning web scrapping since I need it for my work. I wrote the following code:
from selenium import webdriver
chromedriver='/home/es/drivers/chromedriver'
driver = webdriver.Chrome(chromedriver)
driver.implicitly_wait(30)
driver.get('http://crdd.osdd.net/raghava/hemolytik/submitkey_browse.php?ran=1955')
df = pd.read_html(driver.find_element_by_id("table.example.display.datatable").get_attribute('example'))[0]
However, it is showing the following error:
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":"[id="table.example.display.datatable"]"}
(Session info: chrome=103.0.5060.134)
Then I inspect the table that I wanna scrape this table from 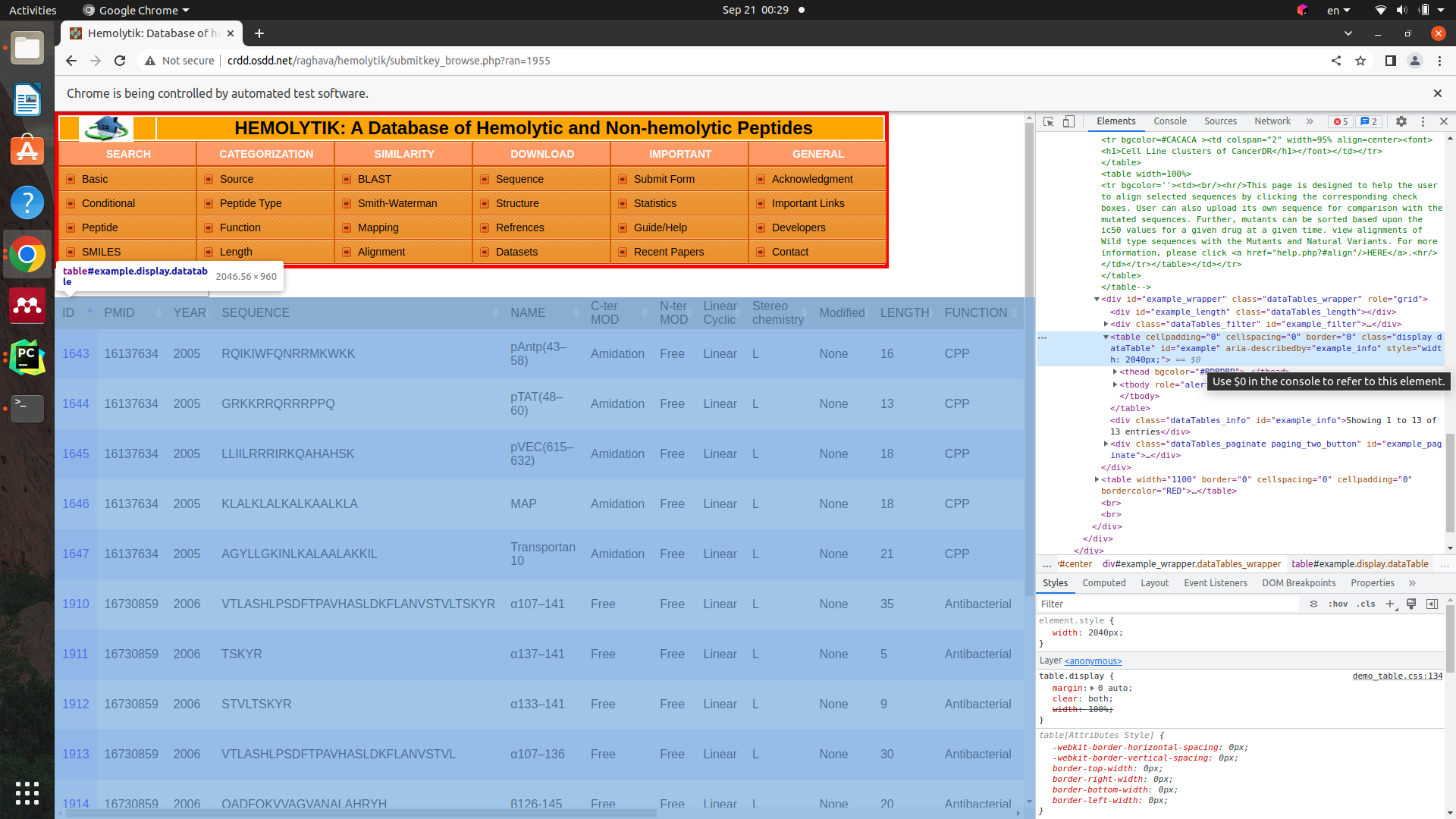
what is the attribute that needs to be included in get_attribute() function in the following line?
df = pd.read_html(driver.find_element_by_id("table.example.display.datatable").get_attribute('example'))[0]
what I should write in the driver.find_element_by_id?
CodePudding user response:
If you want to select table by @id you need
driver.find_element_by_id("example")
By.CSS:
driver.find_element_by_css_selector("table#example")
By.XPATH:
driver.find_element_by_xpath("//table[@id='example'])
If you want to extract @id value you need
.get_attribute('id')
Since there is not much sense in searching by @id to extract that exact @id you might use other attribute of table node:
driver.find_element_by_xpath("//table[@aria-describedby='example_info']").get_attribute('id')
CodePudding user response:
You need to get the outerHTML property of the table first, then call the table element from pandas.
You need to wait for element to be visible. Use explicit wait like WebdriverWait()
driver.get('http://crdd.osdd.net/raghava/hemolytik/submitkey_browse.php?ran=1955')
table=WebDriverWait(driver,10).until(EC.visibility_of_element_located((By.CSS_SELECTOR,"table#example")))
tableRows=table.get_attribute("outerHTML")
df = pd.read_html(tableRows)[0]
print(df)
Import below libraries.
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
import pandas as pd
Output:
ID PMID YEAR ... DSSP Natural Structure Final Structure
0 1643 16137634 2005 ... CCCCCCCCCCCSCCCC NaN NaN
1 1644 16137634 2005 ... CCTTSCCSSCCCC NaN NaN
2 1645 16137634 2005 ... CTTTCGGGHHHHHHHHCC NaN NaN
3 1646 16137634 2005 ... CGGGTTTHHHHHHHGGGC NaN NaN
4 1647 16137634 2005 ... CCSCCCSSCHHHHHHHHHTTC NaN NaN
5 1910 16730859 2006 ... CCCCCCCSSCCSHHHHHHHHTTHHHHHHHHSSCCC NaN NaN
6 1911 16730859 2006 ... CCSCC NaN NaN
7 1912 16730859 2006 ... CCSSSCSCC NaN NaN
8 1913 16730859 2006 ... CCCSSCCSSCCSHHHHHTTHHHHTTTCSCC NaN NaN
9 1914 16730859 2006 ... CCSHHHHHHHHHHHHHCCCC NaN NaN
10 2110 11226440 2001 ... CCCSSCCCBTTBTSSSSSSCSCC NaN NaN
11 3799 9204560 1997 ... CCSSCC NaN NaN
12 4149 16137634 2005 ... CCHHHHHHHHHHHC NaN NaN
[13 rows x 17 columns]
CodePudding user response:
I personally suggest you to use explicit waits instead of implicit ones.
Anyway it's not clear what you're trying to do and what you're looking for. So I will just stick to the question and show you how I would find an element ID:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
options = webdriver.ChromeOptions()
options.add_experimental_option("detach", True)
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
driver.get('http://crdd.osdd.net/raghava/hemolytik/submitkey_browse.php?ran=1955')
df = WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.XPATH, "<XPATH_OF_THE_ELEMENT_YOU_WANT>"))).get_attribute("id")
By the way I suggest you to read the documentation that explains in detail how to locate items.