I have a couple of questions about the group by function. 1. I would like to group by pandas data frame by single column without aggregation. 2. After group by, I would like to split the dataset into several datasets by the month date. So, I wasn't able to do so, I am requesting help. I would appreciate it if you guys can help me. I have provided the code, expected results, and dataset below.
Original dataframe
data = {'month': ['2022-01-01', '2022-02-01', '2022-03-01', '2022-01-01', '2022-02-01', '2022-03-01', '2022-01-01', '2022-02-01', '2022-03-01',],
'Name': ['A', 'A', 'A', 'B', 'B', 'B', 'C', 'C', 'C'],
'num': [1234, 1234, 1234, 456, 456, 456, 456, 100, 200,],
}
df = pd.DataFrame(data)
df
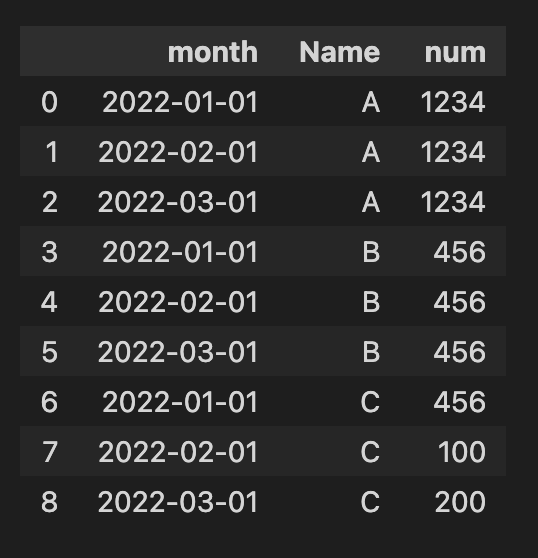
Expected Result for question #1
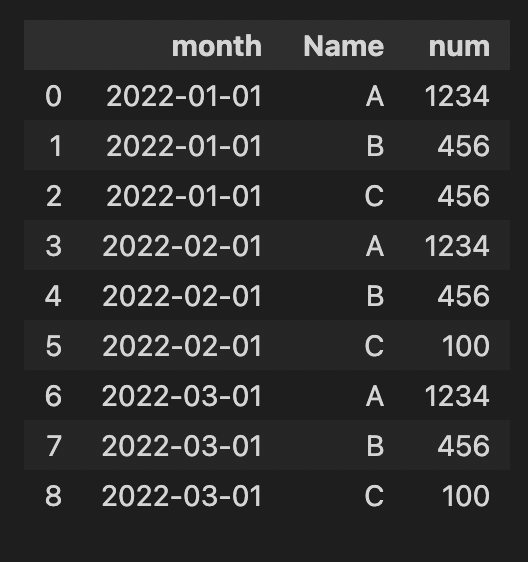
And I want to split the dataset into different datasets like this
Expected Result for question #2
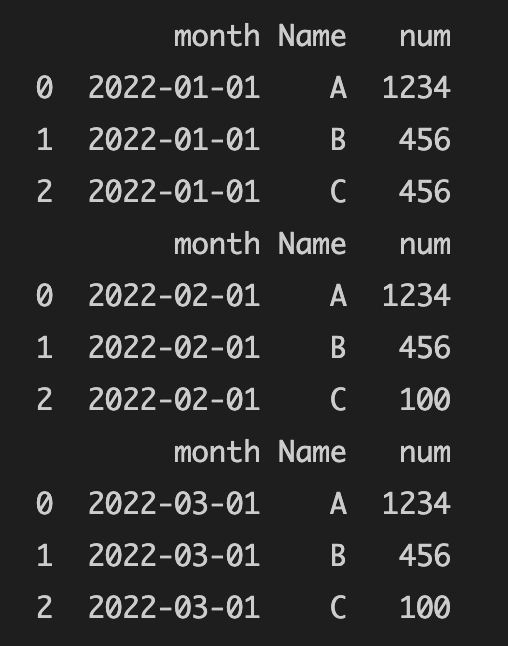
Thank You
CodePudding user response:
try:
df.sort_values(['month', 'Name'])
month Name num
0 2022-01-01 A 1234
3 2022-01-01 B 456
6 2022-01-01 C 456
1 2022-02-01 A 1234
4 2022-02-01 B 456
7 2022-02-01 C 100
2 2022-03-01 A 1234
5 2022-03-01 B 456
8 2022-03-01 C 200
D = []
for i in df['month'].unique():
print(i)
D.append(df.loc[df['month'].eq(i)])
#D is now list of separate dataframes
D[0]
month Name num
0 2022-01-01 A 1234
3 2022-01-01 B 456
6 2022-01-01 C 456
D[1]
month Name num
1 2022-02-01 A 1234
4 2022-02-01 B 456
7 2022-02-01 C 100
type(D[2])
pandas.core.frame.DataFrame
#-----
if you want to sort by only one column, then you need to create this one column as string:
df['monthName'] = df['month'] df['Name']
df.sort_values('monthName')
month Name num monthName
0 2022-01-01 A 1234 2022-01-01A
3 2022-01-01 B 456 2022-01-01B
6 2022-01-01 C 456 2022-01-01C
1 2022-02-01 A 1234 2022-02-01A
4 2022-02-01 B 456 2022-02-01B
7 2022-02-01 C 100 2022-02-01C
2 2022-03-01 A 1234 2022-03-01A
5 2022-03-01 B 456 2022-03-01B
8 2022-03-01 C 200 2022-03-01C
you can drop this column as long as you sort:
df.sort_values('monthName').drop(columns='monthName')
CodePudding user response:
Sort the dataframe using
sort_values:df.sort_values('month')Use
groupbyand assign result to a dictionary like this:dict(tuple(df.groupby('month')))
You can access each separated part of a the dataframe using the month as the dictionary key.