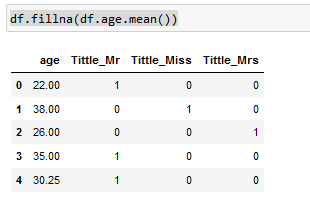
I'm working with Titanic data set and wanted to fill age's na values according to tittles that i get using the names. I want to fill that age value which is in the group(miss, mrs, mr)'s own age mean
| age | Tittle_Mr | Tittle_Miss | Tittle_Mrs |
|---|---|---|---|
| 22 | 1 | 0 | 0 |
| 38 | 0 | 1 | 0 |
| 26 | 0 | 0 | 1 |
| 35 | 1 | 0 | 0 |
| NaN | 1 | 0 | 0 |
I want that na to be Tittle_Mr's age's mean.
In this case 57/2 ~ 28
CodePudding user response:
import pandas as pd
import numpy as np
df = pd.DataFrame({'age': [22 , 38, 26,35,np.nan],"Tittle_Mr":[1,0,0,1,1],"Tittle_Miss":[0,1,0,0,0],"Tittle_Mrs":[0,0,1,0,0]})
indexs=list(np.where(df['age'].isnull())[0])
for i in indexs:
if df["Tittle_Mr"][i]==1:
df["age"][i]=np.mean(df.where(df["Tittle_Mr"]==1))["age"]
elif df["Tittle_Miss"][i]==1:
df["age"][i]=np.mean(df.where(df["Tittle_Miss"]==1))["age"]
else:
df["age"][i]=np.mean(df.where(df["Tittle_Mrs"]==1))["age"]
print(df)
please try this
CodePudding user response:
import pandas as pd
import numpy as np
df = pd.DataFrame({'age': [22 , 38, 26,35,np.nan],"Tittle_Mr":[1,0,0,1,1],"Tittle_Miss":[0,1,0,0,0],"Tittle_Mrs":[0,0,1,0,0]})
df.fillna(df.age.mean())