I have a dataframe that looks like this:
import pandas as pd
score = [[0,1,0,3],[0,2,6,4,0,0],[0,0,0],[0,4,4,2,1,0,0,0]]
group = ["A", "B", "C", "D"]
df = pd.DataFrame([group, score]).T
df.columns = ['Group', 'Score']
You will notice that the score column contains arrays of different lengths. I would like to create two new columns. The want the first new column to be the total number of zeros in the Score columns for that row. I want the second new column to be the last entry in the Score column for that row.
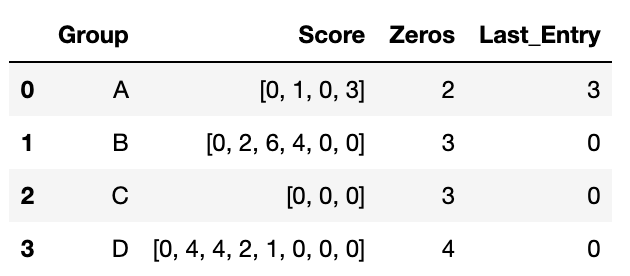
I could write a loop that iterates through every row and perform the required operations. However, I have more than 2 million entries and this would be inefficient.
CodePudding user response:
we can do a generator fed to DataFrame constructor and assign to columns:
>>> df[["Zeros", "Last Entry"]] = pd.DataFrame((sc.count(0), sc[-1])
for sc in df.Score)
>>> df
Group Score Zeros Last Entry
0 A [0, 1, 0, 3] 2 3
1 B [0, 2, 6, 4, 0, 0] 3 0
2 C [0, 0, 0] 3 0
3 D [0, 4, 4, 2, 1, 0, 0, 0] 4 0
I have more than 2 million entries and this would be inefficient.
Well... You have Python lists in a column, so fastness of numeric operations with vectorization is out of the table unfortunately...