I'm trying to select the row that contains the largest number and have accomplished it using this fairly simple query:
SELECT s1.score, name
FROM scores s1
JOIN (
SELECT id, MAX(score) score
FROM scores
GROUP BY id
) s2 ON s1.score = s2.score
All it does (If im not wrong), is just checking if the score field is equal the the MAX(score). So why can't we just do it using one single SELECT statement ?. Something like this:
SELECT id, score
FROM scores
GROUP BY id
HAVING MAX(score) = score
*The code above does not work, I want to ask why it is not working, because its essentially doing the same thing as the previous code I posted
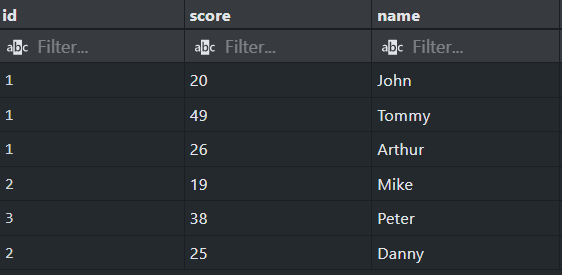
Also here's the data I'm working with:
CodePudding user response:
It returns all persons with same score which the score is the max:
WITH CTE AS (
SELECT *, ROW_NUMBER() OVER(ORDER BY score desc) RN
FROM scores
)
SELECT * FROM CTE
WHERE CTE.RN = 1
CodePudding user response:
Here's what your queries return
DROP table if exists t;
create table t
(id int,score int);
insert into t values
(1,10),(2,20),(3,20);
SELECT s1.id,s1.score
FROM t s1
JOIN (
SELECT id, MAX(score) score
FROM t
GROUP BY id
) s2 ON s1.score = s2.score ;
------ -------
| id | score |
------ -------
| 1 | 10 |
| 2 | 20 |
| 2 | 20 |
| 3 | 20 |
| 3 | 20 |
------ -------
5 rows in set (0.001 sec)
SELECT id, score,max(score)
FROM t
GROUP BY id
HAVING MAX(score) = score
------ ------- ------------
| id | score | max(score) |
------ ------- ------------
| 1 | 10 | 10 |
| 2 | 20 | 20 |
| 3 | 20 | 20 |
------ ------- ------------
3 rows in set (0.001 sec)
Neither result seems to be what you are looking for. You could clarify by posting sample data and desired outcome.
CodePudding user response:
The problem in your second query is the fact that the GROUP BY clause requires all non-aggregated fields within its context. In your case you are dealing with three fields (namely "id", "score" and "MAX(score)") and you're referencing only one (namely "id") inside the GROUP BY clause.
Fixing that would require you to add the non-aggregated "score" field inside your GROUP BY clause, as follows:
SELECT id, score
FROM scores
GROUP BY id, score
HAVING MAX(score) = score
Though this would lead to a wrong aggregation and output, because it would attempt to get the maximum score for each combination of (id, score).
And if you'd attempt to remove the "score" field from both the SELECT and GROUP BY clauses, to solve the non-aggregated columns issue, as follows:
SELECT id
FROM scores
GROUP BY id
HAVING MAX(score) = score
Then the HAVING clause would complain as long it references the "score" field but it is found neither within the SELECT clause nor within the GROUP BY clause.
There's really no way for you to use that kind of notation, as it either violates the full GROUP_BY mode, or it just returns the wrong output.