I'm trying to add a dictionary to a 26x26 dataframe with row and column both go from a to z:
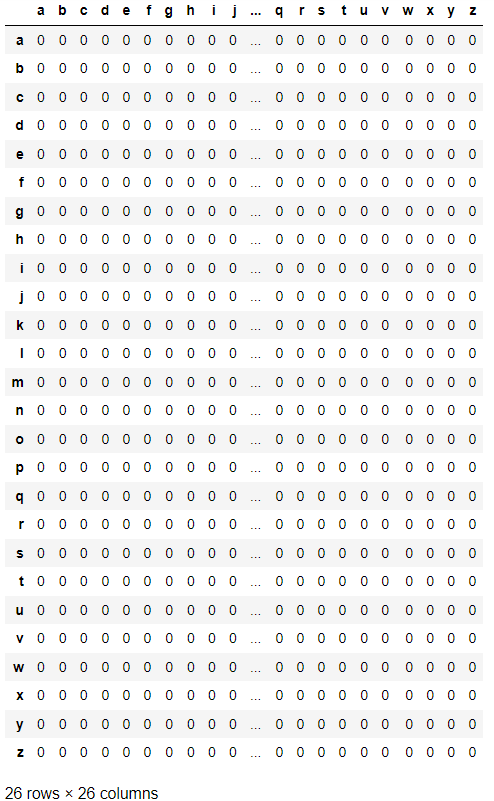
My dictionary where I want to put in the dataframe is:
{'b': 74, 'c': 725, 'd': 93, 'e': 601, 'f': 134, 'g': 200, 'h': 1253, 'i': 355, 'j': 5, 'k': 2, 'l': 324, 'm': 756, 'n': 317, 'o': 88, 'p': 227, 'r': 608, 's': 192, 't': 456, 'u': 152, 'v': 142, 'w': 201, 'x': 51, 'y': 10, 'z': 53}
I want each of my dictionary keys to match the row name of my dataframe, meaning I want this dictionary to be added vertically under the column a. As you can see, the 'a' and 'q' are missing in my dictionary, and I want them to be 0 instead of being skipped. How can I possibly achieve this?
CodePudding user response:
You can use:
df.loc[list(dic), 'a'] = pd.Series(dic)
Or:
df.loc[list(dic), 'a'] = list(dic.values())
Full example:
dic = {'b': 74, 'c': 725, 'd': 93, 'e': 601, 'f': 134, 'g': 200, 'h': 1253,
'i': 355, 'j': 5, 'k': 2, 'l': 324, 'm': 756, 'n': 317, 'o': 88,
'p': 227, 'r': 608, 's': 192, 't': 456, 'u': 152, 'v': 142, 'w': 201,
'x': 51, 'y': 10, 'z': 53}
from string import ascii_lowercase
idx = list(ascii_lowercase)
df = pd.DataFrame(0, index=idx, columns=idx)
df.loc[list(dic), 'a'] = pd.Series(dic)
print(df)
output:
a b c d e f g h i j ... q r s t u v w x y z
a 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
b 74 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
c 725 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
d 93 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
e 601 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
f 134 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
g 200 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
h 1253 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
i 355 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
j 5 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
k 2 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
l 324 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
m 756 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
n 317 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
o 88 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
p 227 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
q 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
r 608 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
s 192 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
t 456 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
u 152 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
v 142 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
w 201 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
x 51 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
y 10 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
z 53 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
[26 rows x 26 columns]
CodePudding user response:
Try iterating through the alphabet using a loop and the chr() function.
dic = {'b': 74, 'c': 725, 'd': 93, 'e': 601, 'f': 134, 'g': 200, 'h': 1253, 'i': 355, 'j': 5, 'k': 2, 'l': 324, 'm': 756, 'n': 317, 'o': 88, 'p': 227, 'r': 608, 's': 192, 't': 456, 'u': 152, 'v': 142, 'w': 201, 'x': 51, 'y': 10, 'z': 53}
for i in range(97,123):
character = chr(i)
if character in dic:
df['a'][character] = dic[character]
else:
df['a'][character] = 0
Assuming df is your pandas data frame.