I'm new to pandas and trying to migrate an indicator from pine script to python. I have a calculation that relies on previous row values that are dynamically computed to get the values of the current row. I have only been able to do this using a for loop, and haven't figured out a good way to do this with numpy or with dataframe.apply. The issue is that this calculation is running extremely slow, too slow to be useable for my purposes. 14 seconds on only 21951 rows.
Does anyone know how to do this in a more efficient way in pandas? Figuring this out will definitely help me when I build out other indicators as most have some sort of reliance of previous row values.
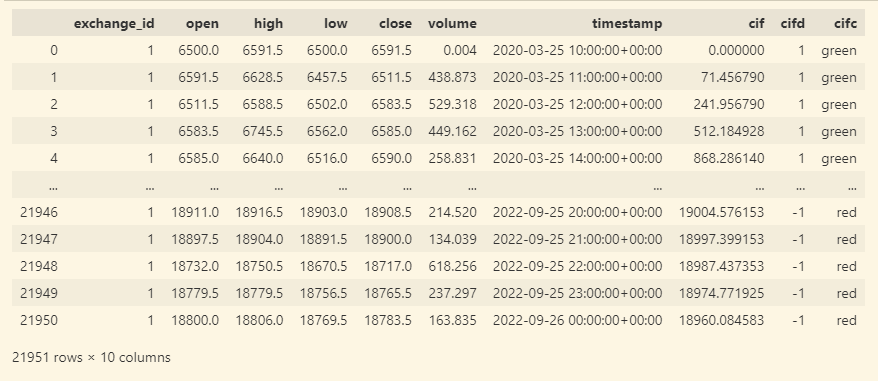
The dataframe looks like:
"""
//
// @author LazyBear
// List of all my indicators:
// https://docs.google.com/document/d/15AGCufJZ8CIUvwFJ9W-IKns88gkWOKBCvByMEvm5MLo/edit?usp=sharing
//
study(title="Coral Trend Indicator [LazyBear]", shorttitle="CTI_LB", overlay=true)
src=close
sm =input(21, title="Smoothing Period")
cd = input(0.4, title="Constant D")
ebc=input(false, title="Color Bars")
ribm=input(false, title="Ribbon Mode")
"""
# @jit(nopython=True) -- Tried this but was getting an error ==> argument 0: Cannot determine Numba type of <class 'pandas.core.frame.DataFrame'>
def coral_trend_filter(df, sm = 21, cd = 0.4):
new_df = df.copy()
di = (sm - 1.0) / 2.0 1.0
c1 = 2 / (di 1.0)
c2 = 1 - c1
c3 = 3.0 * (cd * cd cd * cd * cd)
c4 = -3.0 * (2.0 * cd * cd cd cd * cd * cd)
c5 = 3.0 * cd 1.0 cd * cd * cd 3.0 * cd * cd
new_df['i1'] = 0
new_df['i2'] = 0
new_df['i3'] = 0
new_df['i4'] = 0
new_df['i5'] = 0
new_df['i6'] = 0
for i in range(1, len(new_df)):
new_df.loc[i, 'i1'] = c1*new_df.loc[i, 'close'] c2*new_df.loc[i - 1, 'i1']
new_df.loc[i, 'i2'] = c1*new_df.loc[i, 'i1'] c2*new_df.loc[i - 1, 'i2']
new_df.loc[i, 'i3'] = c1*new_df.loc[i, 'i2'] c2*new_df.loc[i - 1, 'i3']
new_df.loc[i, 'i4'] = c1*new_df.loc[i, 'i3'] c2*new_df.loc[i - 1, 'i4']
new_df.loc[i, 'i5'] = c1*new_df.loc[i, 'i4'] c2*new_df.loc[i - 1, 'i5']
new_df.loc[i, 'i6'] = c1*new_df.loc[i, 'i5'] c2*new_df.loc[i - 1, 'i6']
new_df['cif'] = -cd*cd*cd*new_df['i6'] c3*new_df['i5'] c4*new_df['i4'] c5*new_df['i3']
new_df.dropna(inplace=True)
# trend direction
new_df['cifd'] = 0
# trend direction color
new_df['cifd'] = 'blue'
new_df['cifd'] = np.where(new_df['cif'] < new_df['cif'].shift(-1), 1, -1)
new_df['cifc'] = np.where(new_df['cifd'] == 1, 'green', 'red')
new_df.drop(columns=['i1', 'i2', 'i3', 'i4', 'i5', 'i6'], inplace=True)
return new_df
df = coral_trend_filter(data_frame)
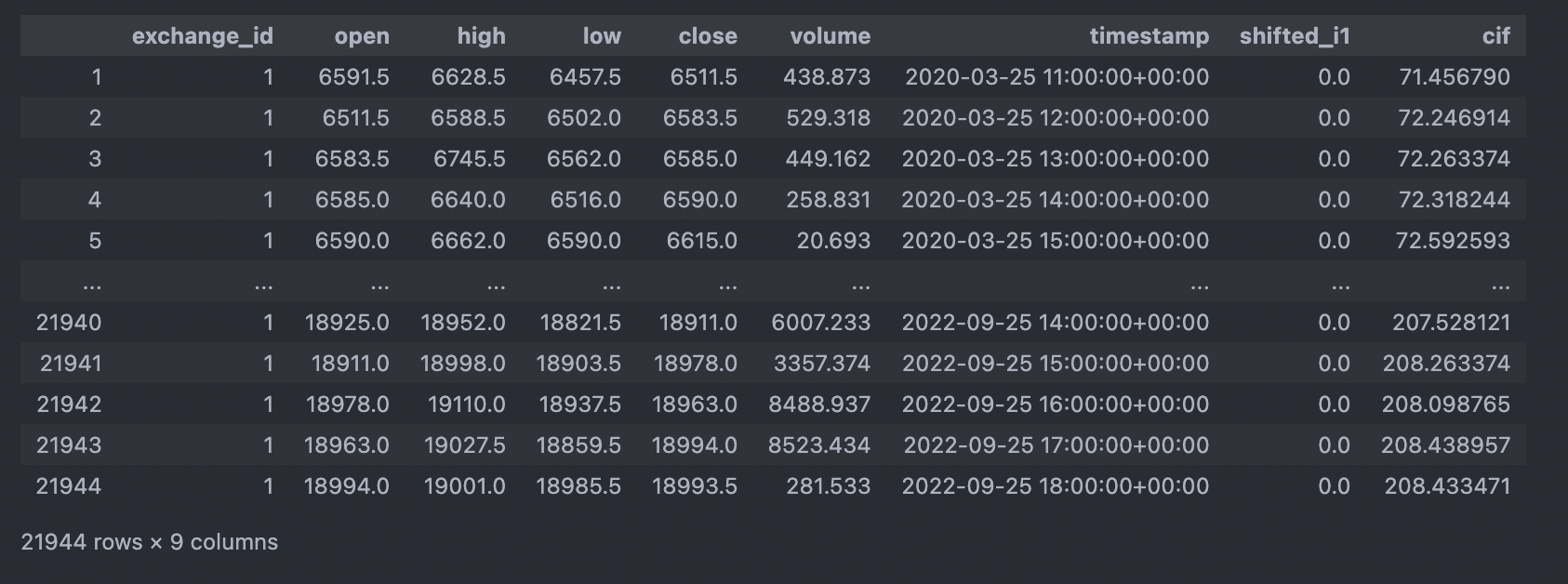
Comment response: One suggestion was to use shift. This does not work due to each row calculation being updated at each iteration. Shifting stores initial values and does not update the shifted columns, thus the computed values are wrong. See this screenshot that does not match the original in the cif column. Also note that I left in shifted_i1 to show that the columns remain 0, which is incorrect for the calculation.
Update:
By changing to using .at instead of .loc I have gotten significantly better performance. My issue may have been I was using the wrong accessor this type of processing.
CodePudding user response:
Edit: Looks like this method won't work due to the serial nature of the problem. Leaving up for posterity.
It's never good to iterate through a dataframe like you're doing with the for loop. Pandas is ultimately just a wrapper for Numpy, so it's best to figure out how to do vectorized array operations. There is basically always a way.
For your case, I would look into using pd.DataFrame.shift to get your i - 1 values in the same row and then use apply (or not - probably not actually) with that new value.
Something like this (for your first couple points):
new_df["shifted_i1"] = new_df["i1"].shift(periods=1)
new_df["i1"] = c1 * new_df["close"] c2 * new_df["shifted_i1"]
new_df["shifted_i2"] = new_df["i2"].shift(periods=1)
new_df["i2"] = c1 * new_df["i1"] c2 * new_df["shifted_i2"])
new_df["shifted_i3"] = new_df["i3"].shift(periods=1)
new_df["i3"] = c1 * new_df["i2"] c2 * new_df["shifted_i3"])
...
After this operation you can delete the shifted columns from the dataframe: new_df.drop(columns=["shifted_i1", "shifted_i2", "shifted_i3"], inplace=True)
CodePudding user response:
Looks like vectorization is only useful when the calculation can be split up and process in parallel per @hpaulj's comment. I have solved the speed issue by converting to array and doing the loop against the array, then saving the result back into the DataFrame. Here's the code, hope it helps anyone else
"""
//
// @author LazyBear
// List of all my indicators:
// https://docs.google.com/document/d/15AGCufJZ8CIUvwFJ9W-IKns88gkWOKBCvByMEvm5MLo/edit?usp=sharing
//
study(title="Coral Trend Indicator [LazyBear]", shorttitle="CTI_LB", overlay=true)
src=close
sm =input(21, title="Smoothing Period")
cd = input(0.4, title="Constant D")
ebc=input(false, title="Color Bars")
ribm=input(false, title="Ribbon Mode")
"""
def coral_trend_filter(df, sm = 25, cd = 0.4):
new_df = df.copy()
di = (sm - 1.0) / 2.0 1.0
c1 = 2 / (di 1.0)
c2 = 1 - c1
c3 = 3.0 * (cd * cd cd * cd * cd)
c4 = -3.0 * (2.0 * cd * cd cd cd * cd * cd)
c5 = 3.0 * cd 1.0 cd * cd * cd 3.0 * cd * cd
new_df['i1'] = 0
new_df['i2'] = 0
new_df['i3'] = 0
new_df['i4'] = 0
new_df['i5'] = 0
new_df['i6'] = 0
close = new_df['close'].to_numpy()
i1 = new_df['i1'].to_numpy()
i2 = new_df['i2'].to_numpy()
i3 = new_df['i3'].to_numpy()
i4 = new_df['i4'].to_numpy()
i5 = new_df['i5'].to_numpy()
i6 = new_df['i6'].to_numpy()
for i in range(1, len(close)):
i1[i] = c1*close[i] c2*i1[i-1]
i2[i] = c1*i1[i] c2*i2[i-1]
i3[i] = c1*i2[i] c2*i3[i-1]
i4[i] = c1*i3[i] c2*i4[i-1]
i5[i] = c1*i4[i] c2*i5[i-1]
i6[i] = c1*i5[i] c2*i6[i-1]
new_df['i1'] = i1
new_df['i2'] = i2
new_df['i3'] = i3
new_df['i4'] = i4
new_df['i5'] = i5
new_df['i6'] = i6
new_df['cif'] = -cd*cd*cd*new_df['i6'] c3*new_df['i5'] c4*new_df['i4'] c5*new_df['i3']
new_df.dropna(inplace=True)
new_df['cifd'] = 0
new_df['cifd'] = np.where(new_df['cif'] < new_df['cif'].shift(), 1, -1)
new_df['cifc'] = np.where(new_df['cifd'] == 1, 'green', 'red')
new_df.drop(columns=['i1', 'i2', 'i3', 'i4', 'i5', 'i6'], inplace=True)
return new_df
CodePudding user response:
You can try to use the following to replace the iteration over rows of the dataframe:
import pandas as pd
import numpy as np
# sample dataframe
rng = np.random.default_rng(0)
new_df = pd.DataFrame({'close': rng.integers(1, 10, 10)})
new_df['i1'] = 0
new_df['i2'] = 0
c1 = 3
c2 = 2
N = len(new_df)
exps = c2**np.r_[:N - 1]
f = lambda x: c1 * np.convolve(new_df.loc[1:, x], exps, mode='full')[:N - 1]
new_df.loc[1:, 'i1'] = f('close')
new_df.loc[1:, 'i2'] = f('i1')
You can compute the values of the columns 'i3', 'i4' etc. by repeating the last line with the new columns names.