I'm trying to implement a Softmax activation that can be applied to arrays of any dimension and softmax can be obtained along a specified axis.
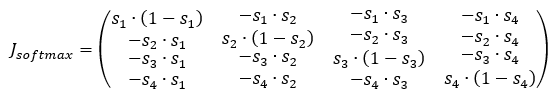
Let's suppose I've an array [[1,2],[3,4]], then if I need the softmax along the rows, I extract each row and apply softmax individually on it through np.apply_along_axis with axis=1. So for the example given above applying softmax to each of [1,2] and [3,4] we get the output as softmax = [[0.26894142, 0.73105858], [0.26894142, 0.73105858]]. So far so good.
Now for the backward pass, let's suppose, I'll have the gradient from the upper layer as upper_grad = [[1,1],[1,1]], so I compute the Jacobian jacobian = [[0.19661193, -0.19661193],[-0.19661193, 0.19661193]] of shape (2,2) for each of the 1D arrays of shape (2,) in softmax and then np.dot it with the corresponding 1D array in upper_grad of shape (2,), so the result of dot product will be an array of shape (2,), the final derivative will be grads = [[0. 0.],[0. 0.]]
I definitely know I'm going wrong somewhere, because while doing gradient checking, I get ~0.90, which is absolutely bonkers. Could someone please help with what is wrong in my approach and how I can resolve it?
import numpy as np
def softmax(arr, axis):
# implementation of softmax for a 1d array
def calc_softmax(arr_1d):
exponentiated = np.exp(arr_1d-np.max(arr_1d))
sum_val = np.sum(exponentiated)
return exponentiated/sum_val
# split the given array of multiple dims into 1d arrays along axis and
# apply calc_softmax to each of those 1d arrays
result = np.apply_along_axis(calc_softmax, axis, arr)
return result
def softmax_backward(arr, axis, upper_grad):
result = softmax(arr, axis)
counter = 0
upper_grad_slices = []
def get_ug_slices(arr_1d, upper_grad_slices):
upper_grad_slices.append(arr_1d)
def backward(arr_1d, upper_grad_slices, counter):
local_grad = -np.broadcast_to(arr_1d, (arr_1d.size, arr_1d.size)) # local_grad is the jacobian
np.fill_diagonal(local_grad, 1 np.diagonal(local_grad))
local_grad*=arr_1d.reshape(arr_1d.size, 1)
grads = np.dot(local_grad, upper_grad_slices[counter]) # grads is 1d array because (2,2) dot (2,)
counter =1 # increment the counter to access the next slice of upper_grad_slices
return grads
# since apply_along_axis doesnt give the index of the 1d array,
# we take the slices of 1d array of upper_grad and store it in a list
np.apply_along_axis(get_ug_slices, axis, upper_grad, upper_grad_slices)
# Iterate over each 1d array in result along axis and calculate its local_grad(jacobian)
# and np.dot it with the corresponding upper_grad slice
grads = np.apply_along_axis(backward, axis, result, upper_grad_slices, counter)
return grads
a = np.array([[1,2],[3,4]])
result = softmax(a, 1)
print("Result")
print(result)
upper_grad = np.array([[1,1],[1,1]])
grads = softmax_backward(a, 1, upper_grad)
print("Gradients")
print(grads)
apply_along_axis documentation - https://numpy.org/doc/stable/reference/generated/numpy.apply_along_axis.html
CodePudding user response:
I'm so dumb. I was using the counter to get the next slice of upper_grad, but the counter was only getting updated locally, so this caused me to get the same slice of upper_grad each time, thus giving invalid gradient. Resolved it using pop method on upper_grad_slices
Updated code
import numpy as np
def softmax(arr, axis):
# implementation of softmax for a 1d array
def calc_softmax(arr_1d):
exponentiated = np.exp(arr_1d-np.max(arr_1d))
sum_val = np.sum(exponentiated)
return exponentiated/sum_val
# split the given array of multiple dims into 1d arrays along axis and
# apply calc_softmax to each of those 1d arrays
result = np.apply_along_axis(calc_softmax, axis, arr)
return result
def softmax_backward(arr, axis, upper_grad):
result = softmax(arr, axis)
upper_grad_slices = []
def get_ug_slices(arr_1d, upper_grad_slices):
upper_grad_slices.append(arr_1d)
def backward(arr_1d, upper_grad_slices):
local_grad = -np.broadcast_to(arr_1d, (arr_1d.size, arr_1d.size)) # local_grad is the jacobian
np.fill_diagonal(local_grad, 1 np.diagonal(local_grad))
local_grad*=arr_1d.reshape(arr_1d.size, 1)
grads = np.dot(local_grad, upper_grad_slices.pop(0)) # grads is 1d array because (2,2) dot (2,)
return grads
# since apply_along_axis doesnt give the index of the 1d array,
# we take the slices of 1d array of upper_grad and store it in a list
np.apply_along_axis(get_ug_slices, axis, upper_grad, upper_grad_slices)
# Iterate over each 1d array in result along axis and calculate its local_grad(jacobian)
# and np.dot it with the corresponding upper_grad slice
grads = np.apply_along_axis(backward, axis, result, upper_grad_slices)
return grads
a = np.array([[1,2],[3,4]])
result = softmax(a, 1)
print("Result")
print(result)
upper_grad = np.array([[1,1],[1,1]])
grads = softmax_backward(a, 1, upper_grad)
print("Gradients")
print(grads)