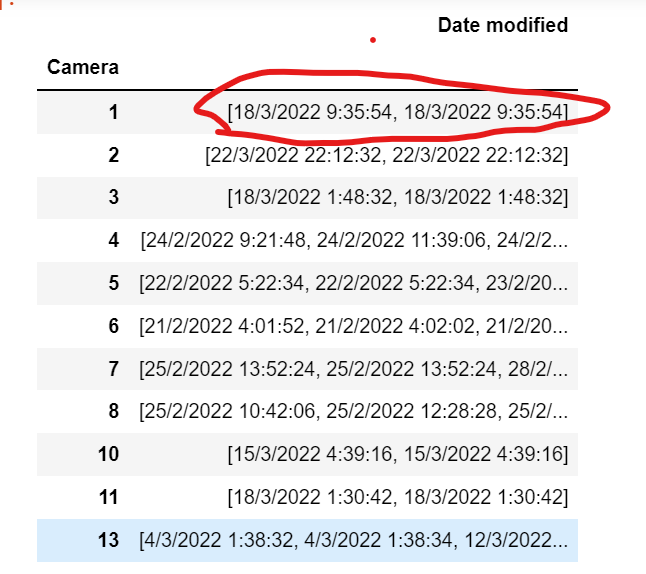
I have data frame like this ( shown in image). I need to remove duplicate from inside of Data frame list. can you help me.
CodePudding user response:
Just building on the answer of @Sachin Kohli and the astute observation of @ Ignatius Reilly, you can use a regex to extract the datetimes and then use the same process
Here's an example dataframe similar to yours above;
df = pd.DataFrame({'Date modified':['[18/3/2022 9:35:54, 18/3/2022 9:35:54]','[18/3/2022 9:35:54, 18/3/2022 9:35:54, 18/3/2022 9:35:55]']})
And the following code will extract the dates and remove duplicates.
import re
date_pattern = r'\d /\d /\d \d :\d :\d '
df["Date modified1"] = df["Date modified"].apply(lambda x:list(set(re.findall(date_pattern,x))))
I've added a new column Date modified1 but obviously you could also just replace the original column as well.
If ordering is important in the lists, then it's probably easiest to use a helper function. The following adds an intermediate step of converting to datetime objects so that ordering works.
import re
import datetime
def helper(s):
re_date_pattern = r'\d /\d /\d \d :\d :\d '
dt_date_pattern = '%d/%m/%Y %H:%M:%S'
date_strings = re.findall(re_date_pattern, s)
date_times = sorted(list(set(map(lambda x: datetime.datetime.strptime(x, dt_date_pattern), date_strings))))
return list(map(lambda x: datetime.datetime.strftime(x, dt_date_pattern), date_times))
And this can be used in a similar way as the example above, but without the need for the lambda function;
df["Date modified1"] = df["Date modified"].apply(helper)
CodePudding user response:
This is what @bn_ln is referring to... doable using apply-lambda function;
df["Date modified1"] = df["Date modified"].apply(lambda x: list(set(x)))