I build a data frame with multivalued in each cell as picture below 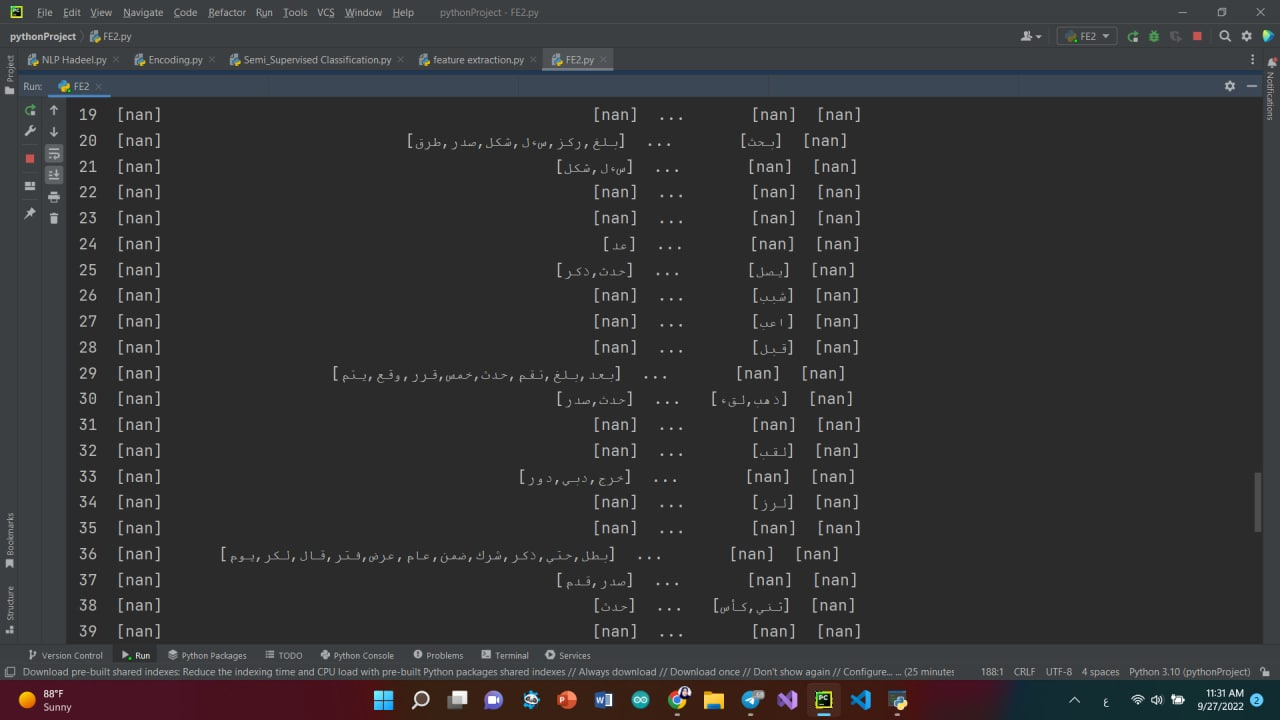 and I want to use logistic regression for classification>>>>
my code is :
and I want to use logistic regression for classification>>>>
my code is :
fds1 = pd.DataFrame(featuresdata)
fds1.fillna('', inplace=True)
from sklearn.model_selection import train_test_split, cross_val_score
X_train, X_test, y_train, y_test = train_test_split(fds1, y, test_size=0.30, random_state=100)
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
score = classifier.score(X_test, y_test)
print("Accuracy for logistic regression:", score)
but there was an error with this code:
File "C:\Users\hp\PycharmProjects\pythonProject\FE2.py", line 317, in CLS2butclick
classifier.fit(X_train, y_train)
File "C:\Users\hp\PycharmProjects\pythonProject\venv\lib\site-packages\sklearn\linear_model\_logistic.py", line 1138, in fit
X, y = self._validate_data(
File "C:\Users\hp\PycharmProjects\pythonProject\venv\lib\site-packages\sklearn\base.py", line 596, in _validate_data
X, y = check_X_y(X, y, **check_params)
File "C:\Users\hp\PycharmProjects\pythonProject\venv\lib\site-packages\sklearn\utils\validation.py", line 1074, in check_X_y
X = check_array(
File "C:\Users\hp\PycharmProjects\pythonProject\venv\lib\site-packages\sklearn\utils\validation.py", line 856, in check_array
array = np.asarray(array, order=order, dtype=dtype)
File "C:\Users\hp\PycharmProjects\pythonProject\venv\lib\site-packages\pandas\core\generic.py", line 2064, in __array__
return np.asarray(self._values, dtype=dtype)
ValueError: setting an array element with a sequence.
How to fix that?
CodePudding user response:
You need to do a label encoding before the training and convert string values to make them understandable for machine.
Refer to https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html