I have data organized by the year it was collected. I would like to know how do I know if there was a trend of increase, decrease or stabilization of the data during the period.
I can do this manually, plotting the plots with ggplot and then visually checking for trends. But this would be unfeasible because I have many columns with data. I would like to do something automatic.
for example visually checking, I see a slight upward trend for the var1 variable:
library(ggplot2)
library(tidyverse)
df<-data.frame(year=c(2000,2001,2001,2002,2000,2002,2000,2001,2002,2001),
var1=c(1,2,3,4,5,6,7,8,9,10),
var2=c(2,3,6,4,8,12,13,4,21,3),
var3=c(0.3,8,6,5,3,2,1,0.6,0.8,0.5),
var4=sample(-5:5, size = 10))
df
ggplot(df, aes(x=year, y=var1))
geom_point(aes(color = "Mean"), size=2.5)
stat_smooth(aes(color = "Trend"), se=FALSE)
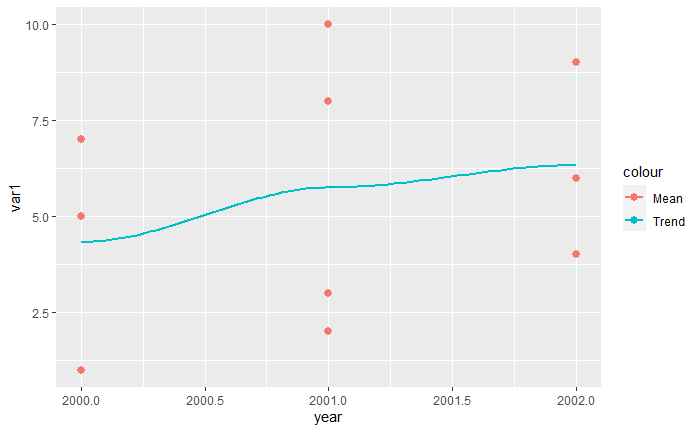
Would there be a possibility for R to do this check automatically? and create a new column indicating the variables increased, decreased or stabilized in variables var1, var2, var3, var4?
CodePudding user response:
This shows for each variable the estimate of the slope and the p-value. Smaller p-values are more significant. Here only var4 has a slope significantly different from zero at the 5% level but you could adjust what cutoff to use which does not change the code.
library(dplyr)
library(broom)
lm(as.matrix(df[-1]) ~ year, df) %>%
tidy %>%
filter(term == "year")
## # A tibble: 4 × 6
## response term estimate std.error statistic p.value
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 var1 year 1.00 1.26 0.792 0.451
## 2 var2 year 2.33 2.49 0.937 0.376
## 3 var3 year 0.583 1.16 0.504 0.628
## 4 var4 year 2.50 1.07 2.34 0.0476
library(lattice)
library(tidyr)
df |>
pivot_longer(-year) |>
xyplot(value ~ year | name, data = _, type = c("p", "r"), as.table = TRUE)
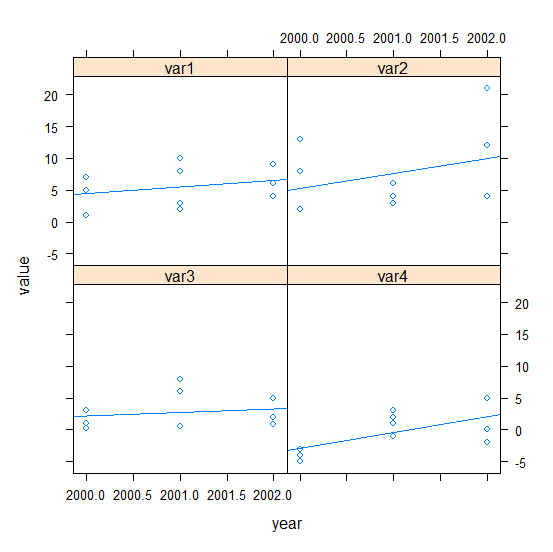
CodePudding user response:
I think what you are looking for is Rob Hyndman's package (which is a part of the tidyverse making manipulations fast and simple) tsibble. It is a time series tibble object.
From there you can use a bunch of tools Rob created with the help and input of other forecasting experts (though he is magnificent on his own) and some of the most influential creators of the Tidyverse in .
He has authored a book, Forecasting Principals & Practice explaining so much about time series, and it is open sourced.
Here is an example from chapter three on how to decompose data (a time series processing method) then extract a plot of the trend:
require(tsibble)
#decompose the data into time series components
dcmp <- df%>%
model(stl = STL(df))
#plot the original points with trend
components(dcmp) %>%
as_tsibble() %>%
autoplot(df, colour="gray")
geom_line(aes(y=trend), colour = "#ffffff")
labs(
y = "Var1",
title = "Something Witty Here"
)
I would take the time to read chapters 1-3 it is not hard reading, it is aimed at application not mathematical understanding. So everything you read will be worthy!
CodePudding user response:
This type of problems generally has to do with reshaping the data. The format should be the long format and the data is in wide format. See this post on how to reshape the data from wide to long format.
After splitting the long format data by groups a model is fit and the extremes of year used to predict from the models. The differences between the first and last can be positive, negative or zero.
library(ggplot2)
suppressPackageStartupMessages(
library(tidyverse)
)
df<-data.frame(year=c(2000,2001,2001,2002,2000,2002,2000,2001,2002,2001),
var1=c(1,2,3,4,5,6,7,8,9,10),
var2=c(2,3,6,4,8,12,13,4,21,3),
var3=c(0.3,8,6,5,3,2,1,0.6,0.8,0.5),
var4=sample(-5:5, size = 10))
old_opts <- options("warn")
options(warn = -1)
df %>%
pivot_longer(-year, names_to = "stat") %>%
ggplot(aes(x=year, y=value, color = stat))
geom_point(size=2.5)
stat_smooth(se = FALSE)
#> `geom_smooth()` using method = 'loess' and formula 'y ~ x'
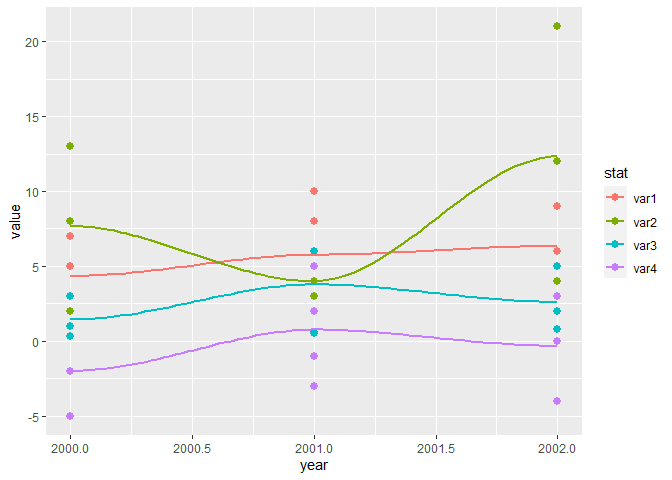
df %>%
pivot_longer(-year, names_to = "stat") %>%
group_split(stat) %>%
map_lgl(\(d) {
fit <- loess(value ~ year, d)
year <- range(d$year)
pred <- predict(fit, newdata = data.frame(year))
diff(pred) > 0
})
#> [1] TRUE TRUE TRUE TRUE
options(old_opts)
Created on 2022-10-05 with reprex v2.0.2