I am trying to reverse the output of 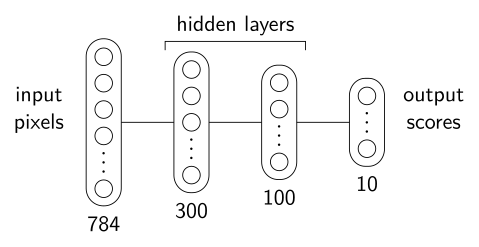
And this is the model implementation
num_classes = 10
input_layer = Input(shape=(img_width * img_height,))
X = Dense(300, activation='relu', kernel_regularizer='l2')(input_layer)
X = Dense(100, activation='relu',kernel_regularizer='l2')(X)
X = Dense(10, activation='relu',kernel_regularizer='l2')(X)
model = Model(inputs=input_layer, outputs=X)
And this is the LRP function to get revelence where arguments are
- W -> weights of the model and in form of list of weights of each layer in order
- B -> Biases of the model and in form of list of weights of each layer in order
- img -> input image in shape of (1,28*28) where 28 is the height & width of image
- pred -> one hot encoded array of which number is the input image
and returns R the revelence of each neuron in each layer
def get_relevance_tf(W,B,img,pred):
L = len(W)
A = [img] [None]*L
for l in range(L):
A[l 1] = tf.nn.relu(tf.matmul(A[l],W[l]) B[l])
R = [0.0]*L [A[L]*(pred)]
for l in range(1,L)[::-1]:
w = W[l]
b = B[l]
z = tf.matmul(A[l],w) b # step 1
s = R[l 1] / z # step 2
c = tf.matmul(s,w,transpose_b=True) # step 3
R[l] = A[l]*c # step 4
w = W[0]
wp = tf.math.maximum(0,w)
wm = tf.math.minimum(0,w)
lb = A[0]*0-1
hb = A[0]*0 1
z = tf.matmul(A[0],w)-tf.matmul(lb,wp)-tf.matmul(hb,wm) 1e-9 # step 1
s = R[1]/z # step 2
c,cp,cm = tf.matmul(s,w,transpose_b=True),tf.matmul(s,wp,transpose_b=True),tf.matmul(s,wm,transpose_b=True) # step 3
R[0] = A[0]*c-lb*cp-hb*cm # step 4
return R
And this is gradient tape function where pred_R is the relevence score of the desired heatmap and model.10.hdf5 is the untrained model
model = tf.keras.models.load_model("model.10.hdf5")
img = tf.convert_to_tensor(X_train[index].reshape(1,784),dtype=tf.float32)
pred = tf.convert_to_tensor(y_train_one_hot[index],dtype=tf.float32)
W = [tf.Variable(i,dtype=tf.float32,trainable=True) for i in model.get_weights()[::2]]
B = [tf.Variable(i,dtype=tf.float32,trainable=True) for i in model.get_weights()[1::2]]
with tf.GradientTape() as tape:
R = get_relevance_tf(W,B,img,pred)
loss = tf.math.reduce_sum(tf.math.abs(R[0]-pred_R[0]))
grads = tape.gradient(loss, [W,B])
print(grads)
This is the output as you can see all the grads are zeros
[[<tf.Tensor: shape=(784, 300), dtype=float32, numpy=
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], dtype=float32)>, <tf.Tensor: shape=(300, 100), dtype=float32, numpy=
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], dtype=float32)>, <tf.Tensor: shape=(100, 10), dtype=float32, numpy=
array([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
...
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
dtype=float32)>, <tf.Tensor: shape=(10,), dtype=float32, numpy=array([-0., -0., -0., -0., -0., -0., -0., -0., -0., -0.], dtype=float32)>]]
I can't understand why the gradients are zeros while there is direct correlation between the weights and the relevence
Things I have tried
- Used autograd same results
- Tried to make it as a custom model where the forward propagation is calculating the relevance score and used optimizer with custom loss function and also same results
CodePudding user response:
I have solved this issue apparently the untrained model's weights were local minima in the loss function thus giving 0 for all weights
Note to future me, start with randomized values