Response to one of my API calls is as below:
{
"requestId": "W2840866301623983629",
"items": [
{
"status": "SUCCESS",
"code": 0,
"apId": "amor:h973hw839sjw8933",
"data": {
"parentVis": 4836,
"parentmeet": 12,
"vis": 908921,
"out": 209481
}
},
{
"status": "SUCCESS",
"code": 0,
"apId": "complex:3d180779a7ea2b05f9a3c5c8",
"data": {
"parentVis": 5073,
"parentmeet": 9,
"vis": 623021,
"out": 168209
}
}
]
}
I'm trying to create a table as below:
----------- ------- ----------------------- --------------- ----------- ----------- -----------
|status |code |apId |parentVis |parentmeet |vis |out |
----------- ------- ----------------------- --------------- ----------- ----------- -----------
|SUCCESS |0 |amor:h973hw839sjw8933 |4836 |12 |908921 |209481 |
|SUCCESS |0 |amor:p0982hny23 |5073 |9 |623021 |168209 |
----------- ------- ----------------------- --------------- ----------- ----------- -----------
I tried to store the API response as string and tried sc.parallelize, but I was unable to achieve the result.
Can someone please help me with the best approach?
CodePudding user response:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.createDataFrame(data['items'])
df.show()
that should do it (assuming your json sits in data dict)
CodePudding user response:
If your response is a string...
s = """{"requestId":"W2840866301623983629","items":[{"status":"SUCCESS","code":0,"apId":"amor:h973hw839sjw8933","data":{"parentVis":4836,"parentmeet":12,"vis":908921,"out":209481}},{"status":"SUCCESS","code":0,"apId":"complex:3d180779a7ea2b05f9a3c5c8","data":{"parentVis":5073,"parentmeet":9,"vis":623021,"out":168209}}]}"""
you can use json library to extract the outer layer and then describe what's inside to extract that too.
from pyspark.sql import functions as F
import json
data_cols = ['parentVis', 'parentmeet', 'vis', 'out']
df = spark.createDataFrame(json.loads(s)['items']).select(
'status', 'code', 'apId',
*[F.col("data")[c].alias(c) for c in data_cols]
)
df.show(truncate=0)
# ------- ---- -------------------------------- --------- ---------- ------ ------
# |status |code|apId |parentVis|parentmeet|vis |out |
# ------- ---- -------------------------------- --------- ---------- ------ ------
# |SUCCESS|0 |amor:h973hw839sjw8933 |4836 |12 |908921|209481|
# |SUCCESS|0 |complex:3d180779a7ea2b05f9a3c5c8|5073 |9 |623021|168209|
# ------- ---- -------------------------------- --------- ---------- ------ ------
CodePudding user response:
Assuming your API response is a dictionary, this should suffice
Store the API response in a dictionary:
dictionary = {
"requestId": "W2840866301623983629",
"items": [
{
"status": "SUCCESS",
"code": 0,
"apId": "amor:h973hw839sjw8933",
"data": {
"parentVis": 4836,
"parentmeet": 12,
"vis": 908921,
"out": 209481
}
},
{
"status": "SUCCESS",
"code": 0,
"apId": "complex:3d180779a7ea2b05f9a3c5c8",
"data": {
"parentVis": 5073,
"parentmeet": 9,
"vis": 623021,
"out": 168209
}
}
]
}
Create the schema based on the input API response providing the datatypes and all from pyspark.sql.types import *
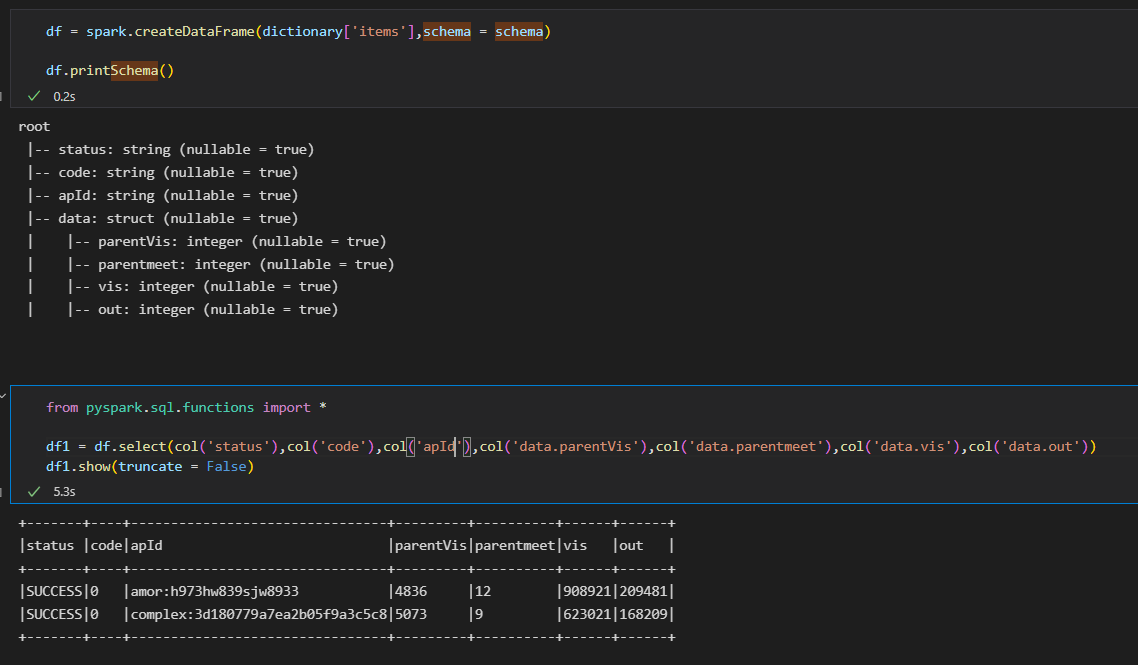
schema = StructType([ \ StructField("status",StringType(),True), \ StructField("code",StringType(),True), \ StructField("apId",StringType(),True), \ StructField("data", StructType([\ StructField("parentVis", IntegerType(),True), \ StructField("parentmeet", IntegerType(),True), \ StructField("vis", IntegerType(),True),\ StructField("out", IntegerType(),True)\ ]) ,True), \ ])Create a dataframe using dictionary and using the above created schema
df = spark.createDataFrame(dictionary['items'],schema = schema)Then create a new dataframe out of by selecting the nested columns as follows: from pyspark.sql.functions import *
df1 = df.select(col('status'),col('code'),col('apId'),col('data.parentVis'),col('data.parentmeet'),col('data.vis'),col('data.out')) df1.show(truncate = False)
Please check the below image for reference: