I do not know Perl and I have a script that should be removing special characters from input.
Script looks like this:
use utf8;
use strict;
use warnings;
use open qw/ :std :encoding(utf-8) /;
use Encode qw(encode decode);
my $str = $ARGV[0];
$str = decode('utf8',shift);
$str =~ s/[^a-zA-Z0-9 \n@.\\,\",\/,\\,<,>,{,},(,),;,:,=,?,¦,%,#,\&, ,*,',!,\$,^,\-,_,–,ä,ü,ö,ß,é,à,è,ù,â,ê,î,ô,û,ç,ë,ï]/ /gi;
print $str;
Sample text that goes as Input:
'04/07/2022 15:16:10 UPCIT\user1 : INFO: The related Ticket INC00112233 has changed it's Status from In Progress to Pending'
you will notice that input text line is quoted by ' ' (single quotes signs) in console look like this
perl /pathtothescript/scriptname.pl 'text to process with the script'
Sample of output:
there will be no output only Program exited with error code 130, because I have terminated script as it was stacked.
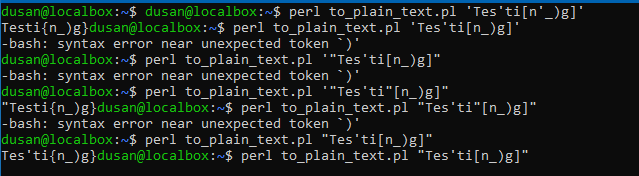
Does anyone have a suggestion on what could be causing for the script to stop when it gets to the ' sign in the text?
this is sample of few test I have been performing on my local machine. Also to point out that tests were done on Ubuntu and script will run on Redhat, I am not 100% sure that this has anything with this...
CodePudding user response:
First, there are a few basic things to straighten out in what the question honestly tries (and very nearly gets right), and to suggest perhaps more structured ways to do it.
The lists of characters to keep have been supplied in a comment.
use strict;
use warnings;
use feature 'say';
use utf8; # for what's in this source
use Encode qw(decode); # for what need be manually decoded
use open qw( :std :encoding(UTF-8) ); # takes care of standard streams
my $str = decode('UTF-8', shift, Encode::FB_CROAK);
# Characters to keep
my $ch_non_ascii = q(ä ü ö ß é à è ù â ê î ô û ç ë ï);
my $punct_symb =
q(@ , . " \/ \ < > { } ( ) # ; : = ? ¦ | % & * ' ! $ ^ - –);
# Note: typed with spaces for readability but then spaces will be kept.
# Can keep it like that but now remove spaces from these variables and
# then they will be removed from input as well, if that is desired
#s/\s //g for $ch_non_ascii, $punct_symb;
my $re_del = qr/[^\w $punct_symb $ch_non_ascii] /xx; # \w --> [a-zA-Z0-9_]
# Or consider using POSIX classes, at least [:punct:]. See text
$str =~ s/$re_del//g;
say $str;
The qr
operator generates a proper regex pattern. The q() is an operator form of single quotes. With /xx modifier all spaces inside a character class are ignored, useful for readability (available from Perl v5.26).
Now running (note double quotes)
script.pl "a,B.!'{)] /\@^~ ö ß ≠"
prints
a,B.!'{) /@^ ö ß
The ~, ], \, and ≠ have been removed as they aren't listed to be kept. If you use [:punct:], instead of listing punctuation/symbols by hand, then only ≠ is removed since the POSIX class includes the others (omitted from the list by an oversight?). The list of included characters is in the perlrecharclass, footnote 5.
Another way, likely far cleaner and safer, is to use POSIX character classes, in particular for punctuation and/or Unicode properties that Perl adds for them. See POSIX character classes in perlrecharclass and perluniprops (with perlunicode and perluniintro).
If that's good enough for your needs then this becomes trivial
$str =~ s/[^ [:alnum:] $ch_non_ascii [:punct:] ] //gxx;
# or
$str =~ s/[^ \p{PosixAlnum} $ch_non_ascii \p{XPosixPunct} ] //gxx;
# or, including full-range unicode
$str =~ s/[^ \p{XPosixAlnum} \p{XPosixPunct} ] //gxx;
The POSIX classes and their corresponding Unicode properties may differ here or there, please see docs and experiment. I space out elements in character classes merely for readability.
These are normal character classes, with [:punct:] and \p{...} in them, so add to them if there are more characters to remove which aren't in the predefined POSIX/Unicode sets.
See linked docs for details.
Comments on some details in the question
The question asks about a
'character in input. That's about how to enter input -- so about your shell, files, pipelines or whatnot. How to read input depends on how it is supplied. If it's directly from the command-line it should generally be double-quoted.If you need to pass to the program very particular things which could confuse the shell, one way to do it is to put them in a file and read the file instead.
Character class just lists characters (no comma between them!), so that in a regex any one of those is matched by it. If it starts with
^, like[^...], then any character that is not listed in it is matched -- that is a "negated" character class. Start in perlretut.A
$stris read from@ARGV-- and then it isshift-ed from it, too. No need for both.Note that writing
utf8orUTF-8may differ; see on this in Encode