In an existing dataframe, how can I add a column with new values in it, but throw these new values from a specific index and increase the dataframe's index size?
As in this example, put the new values from index 2, and go to index 6:
Dataframe:
df = pd.DataFrame({
'Col1':[1, 1, 1, 1],
'Col2':[2, 2, 2, 2]
})
df
Output:
Col1 Col2
0 1 2
1 1 2
2 1 2
3 1 2
New values:
new_values = [3, 3, 3, 3, 3]
Desired Result:
Col1 Col2 Col3
0 1 2 NaN
1 1 2 NaN
2 1 2 3
3 1 2 3
4 NaN NaN 3
5 NaN NaN 3
6 NaN NaN 3
CodePudding user response:
The answer by @anarchy works nicely, a similar approach
df = pd.DataFrame({
'Col1':[1, 1, 1, 1],
'Col2':[2, 2, 2, 2]
})
specific_index_offset = 2
new_data = [3,3,3,3,3]
new_df = pd.DataFrame(
data=[[e] for e in new_data],
columns=['Col3'],
index=range(specific_index_offset, specific_index_offset len(new_data))
)
desired_df = pd.concat([df, new_df], axis=1)
CodePudding user response:
First create a new list and add NaN values that total to the number you want to offset.
Then do a concat.
You can set the series name when you concatnate it and that will be the new column name.
import pandas as pd
import numpy as np
df = pd.DataFrame({
'Col1':[1, 1, 1, 1],
'Col2':[2, 2, 2, 2]
})
new_values = [3, 3, 3, 3, 3]
offset = 2 # set your offset here
new_values = [np.NaN] * offset new_values # looks like [np.NaN, np.NaN, 3, 3, ... ]
new = pd.concat([df, pd.Series(new_values).rename('Col3')], axis=1)
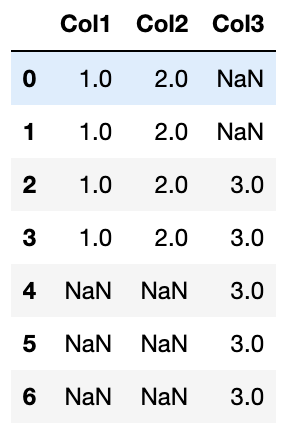
new looks like this,
Col1 Col2 Col3
0 1.0 2.0 NaN
1 1.0 2.0 NaN
2 1.0 2.0 3.0
3 1.0 2.0 3.0
4 NaN NaN 3.0
5 NaN NaN 3.0
6 NaN NaN 3.0
CodePudding user response:
You can also try doing some changes from list level
n = 2 #Input here
xs = [None] * 2
new_values = [3, 3, 3, 3, 3]
new= xs new_values
#create new df
df2 = pd.DataFrame({'col3':new})
df_final = pd.concat([df, df2], axis=1)
print(df_final)
output#
Col1 Col2 col3
0 1.0 2.0 NaN
1 1.0 2.0 NaN
2 1.0 2.0 3.0
3 1.0 2.0 3.0
4 NaN NaN 3.0
5 NaN NaN 3.0
6 NaN NaN 3.0