I have a Series that looks like this
index column
A [41, 13, 4, 50]
A [41, 13, 4, 5]
.
.
.
What I want to do is aggregate the rows of lists, but only the unique values.
The result should look like this:
index column
A [41, 13, 4, 50, 5]
.
.
.
Is there any simple way to do this?
CodePudding user response:
(df.explode('column') # explode list to bring values in rows
.drop_duplicates() # drop duplicates
.groupby('index',as_index=False) # group on index
.agg(list)) # aggregate as list
index column
0 A [41, 13, 4, 50, 5]
if you have a series then
s.explode().drop_duplicates().groupby(level=0).agg(list)
A [41, 13, 4, 50, 5]
B [3, 2, 1]
dtype: object
Data used
s=pd.Series([[41, 13, 4, 50], [41, 13, 4, 5], [5,4,3], [5,2,1]], index=['A', 'A', 'B', 'B'])
s
A [41, 13, 4, 50]
A [41, 13, 4, 5]
B [5, 4, 3]
B [5, 2, 1]
dtype: object
CodePudding user response:
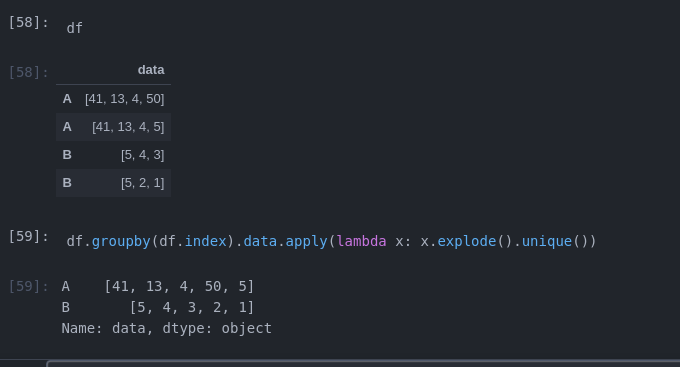
you can also use this:
df.groupby(df.index).column.apply(lambda x: x.explode().unique())
here you first group based on index, then expand everything and return the unique numbers as list
example:
df = pd.DataFrame({'data': [[41, 13, 4, 50], [41, 13, 4, 5], [5,4,3], [5,2,1]]}, index=['A', 'A', 'B', 'B'])
df.groupby(df.index).data.apply(lambda x: x.explode().unique())