I have two dataframes and in the column 'column_to_compare value from df1' I have "sub-categorical" data which I want to match to the "names" to its "categories".
I listed the matching categories below in the matching_cat variable. I don't know if it is the right way to associate my variable to a category.
I want to create a new dataframe which compares these two dataframes with a common id and on the columns categories and names.
import pandas as pd
data1 = {'key_col': ['12563','12564','12565','12566'],
'categories': ['bird', 'dog', 'insect','insect'],'column3': ['some','other','data','there']
}
df1 = pd.DataFrame(data1)
df1
data2 = { 'key_col': ['12563','12564','12565','12566','12567'],
'names': ['falcon', 'golden retriever', 'doberman','spider','spider'],
'column_randomn': ['some','data','here','here','here'] }
df2 = pd.DataFrame(data2)
df2
matching_cat = {'bird': ['falcon', 'toucan', 'eagle'],
'dog': ['golden retriever', 'doberman'],
'insect':['spider','mosquito'] }
So, here are my two dataframes:
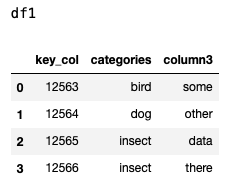
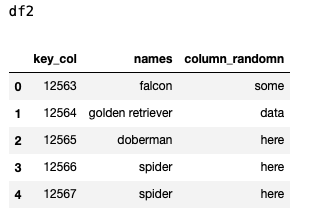
And I want to be able to "map" the values with the categories and output this:
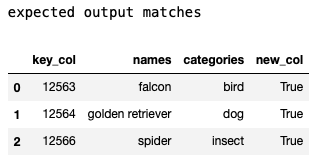

CodePudding user response:
Ok using your example, here is what I came up with:
import pandas as pd
data1 = {'key_col': ['12563','12564','12565','12566'],
'categories': ['bird', 'dog', 'insect','insect'],'column3': ['some','other','data','there']
}
df1 = pd.DataFrame(data1)
data2 = { 'key_col': ['12563','12564','12565','12566','12567'],
'names': ['falcon', 'golden retriever', 'doberman','spider','spider'],
'column_randomn': ['some','data','here','here','here'] }
df2 = pd.DataFrame(data2)
matching_category = {'bird': ['falcon', 'toucan', 'eagle'],
'dog': ['golden retriever', 'doberman'],
'insect': ['spider','mosquito'] }
# Function to compare rows against matching_category
def test(row):
try:
if row['names'] in matching_category[row['categories']]:
val = True
else:
val = False
except:
val=False
return val
# Merge the two dataframes based on 'key_col'
df3 = df1.merge(df2, how='outer', on='key_col')
# Call the test function on each row in the new dataframe (df3)
df3['new_col'] = df3.apply(test, axis=1)
# Drop unwanted columns
df3 = df3.drop(['column3', 'column_randomn'], axis=1)
# Create new dataframes based on whether output matches or not
output_matches = df3[df3['new_col']==True]
output_mismatches = df3[df3['new_col']==False]
# Display the dataframes
print('OUTPUT MATCHES:')
print('================================================')
print(output_matches)
print("")
print('OUTPUT MIS-MATCHES:')
print('================================================')
print(output_mismatches)
OUTPUT:
OUTPUT MATCHES:
================================================
key_col categories names new_col
0 12563 bird falcon True
1 12564 dog golden retriever True
3 12566 insect spider True
OUTPUT MIS-MATCHES:
================================================
key_col categories names new_col
2 12565 insect doberman False
4 12567 NaN spider False