For a classification task I try to compare two models (with SVM) where the difference between the models is just one feature (namely, cult_distance & inst_dist). Even after HP-tuning (using GridSearchCV) both models show the exact same accuracy. When I try a third model with both cult_distance & inst_dist in the model, still the exact same accuracy. My code is below and in the screenshot you see the classification report. As you can see in the report, the minority class is not predicted. I think my model is overfitting but I don't know how to solve this. Note: also when I run the model without any other features than cult_distance & inst_dist, the accuracy is still the same.
features1 = ['inst_dist', 'cult_distance', 'deal_numb', 'acq_sic', 'acq_stat', 'acq_form',
'tar_sic', 'tar_stat', 'tar_form', 'vendor_name', 'pay_method',
'advisor', 'stake', 'deal_value', 'days', 'sic_sim']
X = data.loc[:, features1]
y = data.loc[:, ['deal_status']]
### training the model
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1, train_size = .75)
# defining parameter range
rfc = svm.SVC(random_state = 0)
param_grid = {'C': [0.001],
'gamma': ['auto'],
'kernel': ['rbf'],
'degree':[1]}
grid = GridSearchCV(rfc, param_grid = param_grid, refit = True, verbose = 2,n_jobs=-1)
# fitting the model for grid search
grid.fit(X_train, y_train)
# print best parameter after tuning
grid_predictions = grid.predict(X_test)
# print classification report
print(classification_report(y_test, grid_predictions))
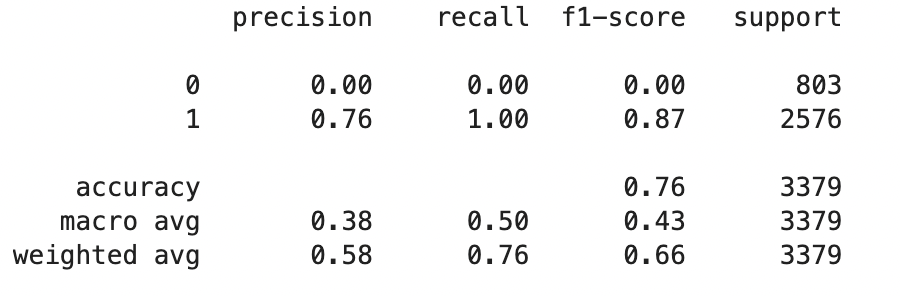
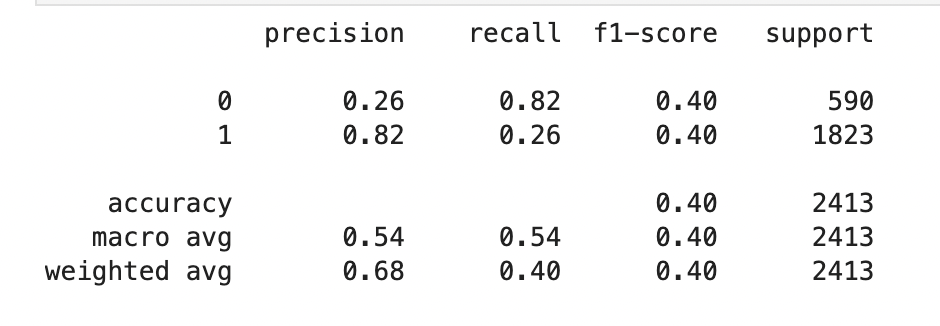
EDIT: After a useful comment, I used class_weight to insert in the dataset. However the accuracy of the data is much lower than the baseline of 0.76?
CodePudding user response:
The problem seems to be connected with unbalanced dataset. One class present much more in your dataset, so model learns to predict only that class. There are numerous ways to combat that, the simplest one is to adjust class_weight parameter in your model. In your situation it should be around class_weight = {0 : 3.2, 1 : 1} as second class is 3 times more popular. You can calculate that using compute_class_weight from sklearn.
Hope that was helpful!