I have a data set that has 2 rows per part (one for 2021, one for 2022) and 16 columns. One of those columns is the Volume loss in dollars for 2022 (the volume loss in dollars for 2021 is always null value). I want to sort the data set by the volume loss in 2022 but keep the two rows per part together according to the image attached.
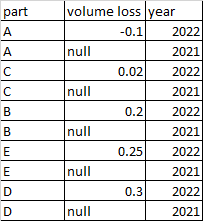
I tried using Partition by:
SELECT *,
ROW_NUMBER() OVER (PARTITION BY part ORDER BY volume_loss DESC) as [row_number]
FROM DF
CodePudding user response:
You can use a subquery or CTE to get ranks by Part Number for CY 2022, then join on part. You didn't mention your rdbms, but here's a postgres version that can be adapted to your dbms...
with part_ranks as (
select part,
row_number() over (order by volume_loss asc) as rn
from my_table
where year = 2022
)
select t.*
from my_table t
join part_ranks r
on t.part = r.part
order by r.rn, year desc;
| part | volume_loss | year |
|---|---|---|
| A | -0.1 | 2022 |
| A | 2021 | |
| C | 0.02 | 2022 |
| C | 2021 | |
| B | 0.2 | 2022 |
| B | 2021 | |
| E | 0.25 | 2022 |
| E | 2021 | |
| D | 0.3 | 2022 |
| D | 2021 |