Here is my data:
mydata <- structure(list(group = c("a", "a", "a", "a", "a", "a", "a", "a",
"a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a",
"a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a",
"a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a",
"a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a",
"a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a",
"a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a",
"a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a",
"a", "b", "b", "b", "b", "b", "b", "b", "b", "b", "b", "b", "b",
"b", "b", "b", "b", "b", "b", "b", "b", "b", "b", "b", "b", "b",
"b", "b", "b", "b", "b", "b", "b", "b", "b", "b", "b", "b", "b",
"b", "b", "b", "b", "b", "b", "b", "b", "b", "b", "b", "b"),
age = c(27, 21, 27, 21, 24, 27, 27, 30, 27, 27, 27, 27, 27,
21, 27, 24, 24, 27, 21, 24, 30, 30, 24, 24, 27, 18, 27, 24,
18, 18, 9, 12, 15, 12, 15, 12, 9, 9, 12, 15, 15, 18, 18,
15, 21, 21, 15, 21, 12, 21, 15, 30, 21, 18, 21, 21, 24, 21,
24, 24, 27, 24, 18, 27, 9, 21, 27, 21, 21, 21, 27, 24, 27,
24, 30, 30, 30, 27, 27, 24, 27, 27, 24, 24, 30, 27, 27, 30,
21, 24, 21, 27, 24, 24, 24, 24, 24, 24, 24, 21, 34, 25, 27,
35, 27, 28, 32, 33, 32, 9, 9, 8, 15, 29, 30, 10, 40, 31,
27, 40, 28, 31, 17, 19, 35, 29, 23, 15, 16, 26, 27, 25, 23,
24, 25, 25, 13, 36, 25, 27, 35, 35, 24, 21, 25, 10, 23, 5,
34, 21)), row.names = c(1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L,
10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L,
23L, 24L, 25L, 26L, 27L, 28L, 29L, 30L, 31L, 32L, 33L, 34L, 35L,
36L, 37L, 38L, 39L, 40L, 41L, 42L, 43L, 44L, 45L, 46L, 47L, 48L,
49L, 50L, 51L, 52L, 53L, 54L, 55L, 56L, 57L, 58L, 59L, 60L, 61L,
62L, 63L, 64L, 65L, 66L, 67L, 68L, 69L, 70L, 71L, 72L, 73L, 74L,
75L, 76L, 77L, 78L, 79L, 80L, 81L, 82L, 83L, 84L, 85L, 86L, 87L,
88L, 89L, 90L, 91L, 92L, 93L, 94L, 95L, 96L, 97L, 98L, 99L, 100L,
101L, 102L, 103L, 104L, 105L, 106L, 107L, 108L, 109L, 110L, 111L,
112L, 113L, 114L, 115L, 116L, 117L, 118L, 119L, 120L, 121L, 122L,
123L, 124L, 125L, 126L, 127L, 128L, 129L, 130L, 132L, 133L, 134L,
135L, 136L, 137L, 138L, 139L, 140L, 141L, 142L, 143L, 144L, 145L,
146L, 147L, 148L, 149L, 150L, 151L), class = "data.frame")
Here is my code to plot points with jittering (ggplot2::geom_point) and their distribution (ggdist::stat_halfeye):
library(ggplot2)
library(ggdist)
ggplot(mydata, aes(x = group, y = age))
ggdist::stat_halfeye(
adjust = .5,
width = .6,
.width = 0,
justification = -.3,
point_colour = NA)
geom_point(
size = 1.3,
alpha = .3,
position = position_jitter(
seed = 1, width = .1
)
)
Here is the figure:
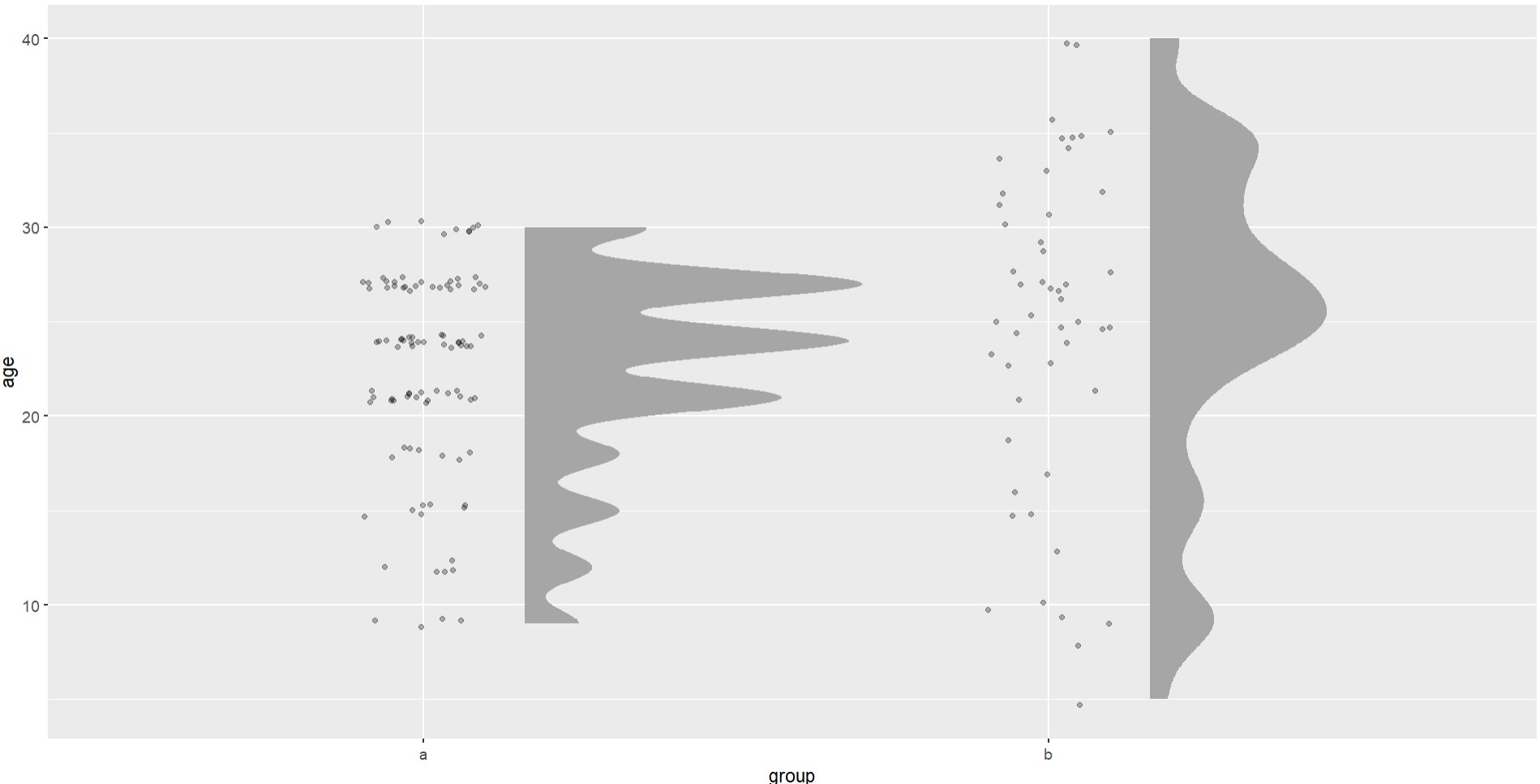
Age values for both groups are integers, however, it is clear that points are jittered to a larger degree in group b. Similarly, the distribution for group b is much smoother than group a. Why is this the case and how could I may the distribution for group a smoother, as is the case for group b?
CodePudding user response:
Your data is all integers in both groups, but not at all evenly distributed. Look at this:
mydata %>% group_by(group) %>% summarize(n_distinct(age))
# # A tibble: 2 × 2
# group `n_distinct(age)`
# <chr> <int>
# 1 a 8
# 2 b 25
mydata %>% count(group, age)
# group age n
# 1 a 9 4
# 2 a 12 5
# 3 a 15 7
# 4 a 18 7
# 5 a 21 19
# 6 a 24 24
# 7 a 27 25
# 8 a 30 9
# 9 b 5 1
# 10 b 8 1
# 11 b 9 2
# 12 b 10 2
# 13 b 13 1
# 14 b 15 2
# 15 b 16 1
# 16 b 17 1
# 17 b 19 1
# 18 b 21 2
# 19 b 23 3
# 20 b 24 2
# 21 b 25 6
# 22 b 26 1
# 23 b 27 5
# 24 b 28 2
# 25 b 29 2
# 26 b 30 1
# 27 b 31 2
# 28 b 32 2
# 29 b 33 1
# 30 b 34 2
# 31 b 35 4
# 32 b 36 1
# 33 b 40 2
Group a has 8 distinct age values, and almost all the ages are 21, 24, and 27, each with counts of 19 or more. No other integers from 19-29 are represented in group a.
Group b has 25 distinct age groups, with the max count being 6. Much more evenly distributed, far fewer gaps than group a.
it is clear that points are jittered to a larger degree in group b.
This is not at all clear to me. From the ?position_jitter help page's description of the height and width arguments: "If omitted, defaults to 40% of the resolution of the data: this means the jitter values will occupy 80% of the implied bins". I'm not sure if this "resolution of the data" is calculated by group or not. I doubt it is, my guess is the jitter is evenly applied for both groups. (Actually, I would say it is clear that the height jitter in group a in your plot is not taking up 80% of the bin width, so the points are jittered to the same amount in both groups.) In either case, I'd suggest specifying the height of the jitter as well as the width, and keeping it small, say 0.1 or less.
Similarly, the distribution for group b is much smoother than group a.
Correct, the data in group b is distributed much more smoothly than group a. This is an accurate reflection of your data.