Am trying to create manager hierarchy columns using just Employee ID and Manager Email Address columns. The Name column has unique values while there are duplicates in the Mgr_Email column (ie each employee has one manager but a manager could have multiple reports in their organisation).
The data looks like this
Name Mgr_Email
Sally Po [email protected]
Sean Sea [email protected]
Jacob Hin [email protected]
Tim Buick [email protected]
Kris Olt [email protected]
Cindy Myers [email protected]
and the desired outcome is this. There could be many levels of manager hierarchy and not just 4 hierarchy columns shown in the example.
Name Mgr_Email Mgr_Lvl_01 Mgr_lvl_02 Mgr_lvl_03 Mgr_lvl_04
Sally Po [email protected] [email protected]
Sean Sea [email protected] [email protected] [email protected]
Jacob Hin [email protected] [email protected] [email protected] [email protected] [email protected]
Tim Buick [email protected] [email protected] [email protected] [email protected]
Kris Olt [email protected] [email protected] [email protected] [email protected]
Cindy Myers [email protected] [email protected] [email protected]
I have tried this but it does not work
i=1
df['Level 0'] = df['Manager Email Address']
while df.notna().sum().ne(1).all():
df[f'Mgr_Lvl {i}'] = df[f'Mgr_Lvl {i-1}'].map(df.set_index('Name')['Mgr_Email'])
i =1
df = df.drop('Level 0',axis=1)
df['Mgr_Lvl_01'] = df.loc[:,f'Mgr_Level {i-1}'].ffill().bfill()
Appreciate any help I could get, thank you.
CodePudding user response:
You cannot solve this easily with 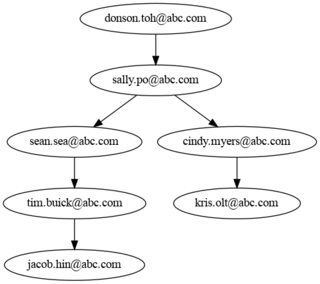
A useful tool is networkx:
# make email address from Name
# (best would be to already have an identifier to map names)
df['Email'] = df['Name'].str.lower().str.replace(r'(\w ) (\w )', r'\1.\[email protected]', regex=True)
import networkx as nx
# create graph
G = nx.from_pandas_edgelist(df, source='Mgr_Email', target='Email',
create_using=nx.DiGraph)
# find roots (= top managers)
roots = [n for n,d in G.in_degree() if d==0]
# ['[email protected]']
# for each employee, find the hierarchy
df2 = (pd.DataFrame([next((p for root in roots for p in nx.all_simple_paths(G, root, node)), [])[:-1]
for node in df['Email']], index=df.index)
.rename(columns=lambda x: f'Mgr_Lvl_{x 1:02d}')
)
# join to original DataFrame
out = df.drop(columns='Email').join(df2)
output:
Name Mgr_Email Mgr_Lvl_01 Mgr_Lvl_02 Mgr_Lvl_03 Mgr_Lvl_04
0 Sally Po [email protected] [email protected] None None None
1 Sean Sea [email protected] [email protected] [email protected] None None
2 Jacob Hin [email protected] [email protected] [email protected] [email protected] [email protected]
3 Tim Buick [email protected] [email protected] [email protected] [email protected] None
4 Kris Olt [email protected] [email protected] [email protected] [email protected] None
5 Cindy Myers [email protected] [email protected] [email protected] None None