pandasdf=pd.DataFrame(
{
"A": [1, 2, 3, 4, 5],
"fruits": ["banana", "banana", "apple", "apple", "banana"],
"B": [5, 4, 3, 2, 1],
"cars": ["beetle", "audi", "beetle", "beetle", "beetle"],
"optional": [28, 300, None, 2, -30],
}
)
pandasdf.groupby(["fruits","cars"])['B'].sum().unstack()
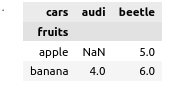
How can i create an equivalent truth table in polars?
Something like the below table into a truth table
df=pl.DataFrame(
{
"A": [1, 2, 3, 4, 5],
"fruits": ["banana", "banana", "apple", "apple", "banana"],
"B": [5, 4, 3, 2, 1],
"cars": ["beetle", "audi", "beetle", "beetle", "beetle"],
"optional": [28, 300, None, 2, -30],
}
)
df.groupby(["fruits","cars"]).agg(pl.col('B').sum()) #->truthtable
The efficiency of the code is important as the dataset is too large (for using it with apriori algorithm)
The unstack function in polars is different, polars alterative for pd.crosstab would also work.
CodePudding user response:
It seems like you want tot do a pivot.
df = pl.DataFrame(
{
"A": [1, 2, 3, 4, 5],
"fruits": ["banana", "banana", "apple", "apple", "banana"],
"B": [5, 4, 3, 2, 1],
"cars": ["beetle", "audi", "beetle", "beetle", "beetle"],
"optional": [28, 300, None, 2, -30],
}
)
df.pivot(values="B", index="cars", columns="fruits", aggregate_fn=pl.element().sum())
shape: (2, 3)
┌────────┬────────┬───────┐
│ cars ┆ banana ┆ apple │
│ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ i64 │
╞════════╪════════╪═══════╡
│ beetle ┆ 6 ┆ 5 │
├╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┤
│ audi ┆ 4 ┆ null │
└────────┴────────┴───────┘