**Here is the code I'm trying to execute to encode the values of the first column of my data set using dummy values **
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Data.csv')
# divide dataset to dependent variable(features) and independent variable(output)
X = dataset.iloc[: , :-1].values
y = dataset.iloc[: ,3].values
# taking care of missing data
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
# apply the simpleImputer on the x from column[age to salary]
imputer = imputer.fit(X[: , 1:3 ])
# replace the missing data by the processed data
X[: , 1:3 ] = imputer.transform(X[: , 1:3 ])
# Encoding categorical data [country]
from sklearn.preprocessing import LabelEncoder , OneHotEncoder
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[: ,0])
# creates a binary column for each category
onehotencoder_X = OneHotEncoder(categories=['France','Germany','Spain'])
X_1 = onehotencoder_X.fit_transform(X[: ,0].reshape(-1,1)).toarray()
X = np.concatenate([X_1,X[: , 1:]],axis = 1)
the data that i work on
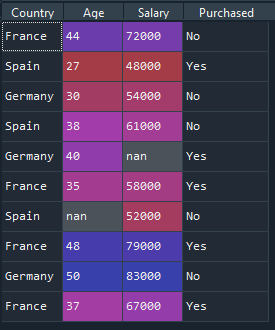
i'm getting an error

Can anyone help me fix this?
Can anyone help me fix this?
CodePudding user response:
A more convenient way to encode categorical features is using pandas' facilities. I implement this as follows:
df = pd.DataFrame({'feature':['French', 'Germany', 'Germany', 'Spain']})
labelencoder = LabelEncoder()# Assigning numerical values and storing in another column
df['categorical_feature'] = labelencoder.fit_transform(df['feature'])
enc = OneHotEncoder(handle_unknown='ignore')# passing cat column (label encoded values of df)
enc_df = pd.DataFrame(enc.fit_transform(df[['categorical_feature']]).toarray(), columns=labelencoder.classes_)# merge with main df on key values
df = df.join(enc_df)
df
output:
feature categorical_feature French Germany Spain
0 French 0 1.0 0.0 0.0
1 Germany 1 0.0 1.0 0.0
2 Germany 1 0.0 1.0 0.0
3 Spain 2 0.0 0.0 1.0
CodePudding user response:
**the Answer **
from sklearn.preprocessing import LabelEncoder , OneHotEncoder
import numpy as np
#label_encoder object
label_encoder_X = LabelEncoder()
#Encode labels in columns
X[ : , 0] = label_encoder_X.fit_transform(X[: , 0])
# creates a binary column for each category
onehot_encoder=OneHotEncoder(categories=[[ 0 , 1 , 2 ]])
onehot_encoder=onehot_encoder.fit_transform(X[:,0].reshape(-1, 1)).toarray()
X = np.concatenate([onehot_encoder,X[:,1:]], axis=1)
{kind=link}