I'm trying to make a dataframe pulled from an excel file more user-friendly by creating a "Type" column.
The data can be found here: 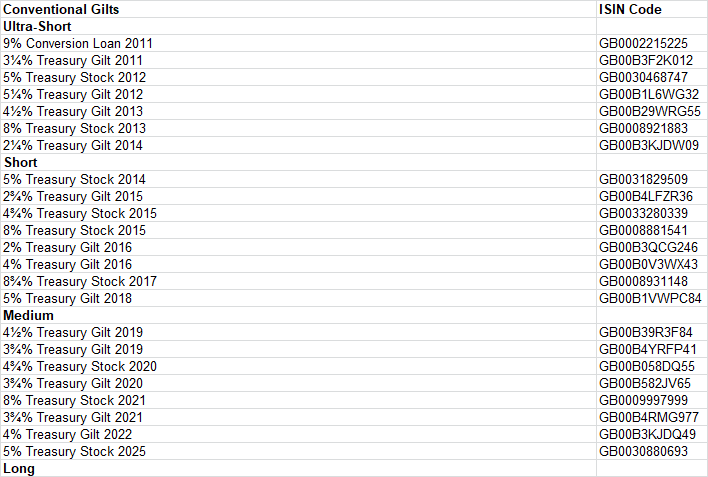
What I'd like to do is is change title "Conventional Gilts" to being "Name", and create a "Type" column that has the different categories pulled from their grouped title. In the linked file, the "Types" would be: "Ultra-Short", "Short", "Medium", "Long", "Index-linked Gilts (3-month Indexation Lag)", "Undated Gilts (non "rump")", and ""Rump" Gilts".
While I feel I would need to do some form of pattern recognition using a package like grepl, I'm not sure how I can achieve this from a 'dynamic' perspective (changing if new categories are created).
Any advice on how to achieve this (or even achieve this in a function) would be greatly appreciated.
CodePudding user response:
I don't know about a single function to do all this; the data is haphazardly arranged and needs to be fixed "manually", for example:
library(readxl)
library(tidyverse)
gilts <- read_xls("C:/Users/Administrator/Documents/gilts.xls")
gilts %>%
filter(!apply(gilts, 1, function(x) all(is.na(x)))) %>%
filter(seq(nrow(.)) < 44) %>%
select(1:7) %>%
filter(seq(nrow(.)) != 1) %>%
setNames(unlist(slice(., 1))) %>%
filter(seq(nrow(.)) != 1) %>%
mutate(splitter = cumsum(is.na(`ISIN Code`))) %>%
group_by(splitter) %>%
mutate(Type = first(`Conventional Gilts`)) %>%
summarize(across(everything(), ~.x[-1])) %>%
ungroup() %>%
select(-1) %>%
select(c(8, 1:7)) %>%
rename(Name = `Conventional Gilts`) %>%
mutate(across(c(4, 5, 7),
~ as.Date(as.numeric(.x), origin = "1899-12-30"))) %>%
mutate(across(contains("million"), as.numeric))
#> `summarise()` has grouped output by 'splitter'. You can override using the
#> `.groups` argument.
#> # A tibble: 37 x 8
#> Type Name ISIN ~1 Redempti~2 First Is~3 Divid~4 Current/~5 Total~6
#> <chr> <chr> <chr> <date> <date> <chr> <date> <dbl>
#> 1 Ultra-Short 9% Conv~ GB0002~ 2011-07-12 1987-07-12 12 Jan~ 2011-07-01 7312.
#> 2 Ultra-Short 3¼% Tre~ GB00B3~ 2011-12-07 2008-11-14 7 Jun/~ 2011-05-26 15747
#> 3 Ultra-Short 5% Trea~ GB0030~ 2012-03-07 2001-05-25 7 Mar/~ 2011-08-26 26867.
#> 4 Ultra-Short 5¼% Tre~ GB00B1~ 2012-06-07 2007-03-16 7 Jun/~ 2011-05-26 25612.
#> 5 Ultra-Short 4½% Tre~ GB00B2~ 2013-03-07 2008-03-05 7 Mar/~ 2011-08-26 33787.
#> 6 Ultra-Short 8% Trea~ GB0008~ 2013-09-27 1993-04-01 27 Mar~ 2011-09-16 8378.
#> 7 Ultra-Short 2¼% Tre~ GB00B3~ 2014-03-07 2009-03-20 7 Mar/~ 2011-08-26 29123.
#> 8 Short 5% Trea~ GB0031~ 2014-09-07 2002-07-25 7 Mar/~ 2011-08-26 36579.
#> 9 Short 2¾% Tre~ GB00B4~ 2015-01-22 2009-11-04 22 Jan~ 2011-07-13 28181.
#> 10 Short 4¾% Tre~ GB0033~ 2015-09-07 2003-09-26 7 Mar/~ 2011-08-26 33650.
#> # ... with 27 more rows, and abbreviated variable names 1: `ISIN Code`,
#> # 2: `Redemption Date`, 3: `First Issue Date`, 4: `Dividend Dates`,
#> # 5: `Current/Next \nEx-dividend Date`,
#> # 6: `Total Amount in Issue \n(£ million nominal)`
Created on 2022-10-30 with reprex v2.0.2
CodePudding user response:
Different approach, premised on the fact that all the gilts start with numbers and the types do not. Makes use of janitor which has super helpful functions for cleaning up messy imported data like this.
library(tidyverse)
library(readxl)
library(janitor)
import_gilts <- read_excel("20221031 - Gilts in Issue.xls.xls", skip = 7)
gilts <- import_gilts %>%
filter(!str_detect(1, "^Note|^Page")) %>%
rename(Name = `Conventional Gilts`) %>%
remove_empty(which = "rows") %>%
mutate(Type = case_when(str_detect(Name, "^[^0-9]") ~ Name,
TRUE ~ NA_character_),
.before = Name) %>%
fill(Type, .direction = "down") %>%
arrange(desc(...9)) %>%
row_to_names(row_number = 2) %>%
rename(Type = 1,
Name = 2) %>%
filter(Type != Name)
Quick draft so there's certainly room for improvement.
Should be able to be turned into a function as long as the number of imported columns and number of rows to skip reading in the file stay the same.