I am attempting to query multiple columns in order to display the heaviest ship for each builder/company name.
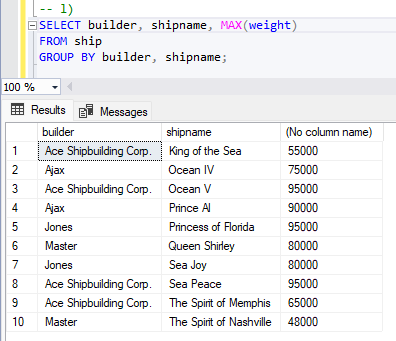
When using my above query I instead receive the results for every ships weight instead of the heaviest ship for each builder. I have spent a few hours trying to discern what is needed to cause the builder column to be distinct.
CodePudding user response:
You have to remove 'shipname' from the group by list to get the max weight for each builder, then join the query to the original table to get the ship name as the following:
select T.builder, T.shipname, T.weight
from ship T join
(
select builder, max(weight) mx
from ship
group by builder
) D
on T.builder=D.builder and T.weight=D.mx
order by T.builder
You may also use DESNE_RANK() function to get the required results as the following:
select top 1 with ties
builder, shipname, weight
from ship
order by dense_rank() over (partition by builder order by weight desc)
See a demo on SQL Server (I supposed that you are using SQL Server from the posted image).
CodePudding user response:
You don't need to apply a GROUP BY clause in this situation. It will be sufficient to check whether the ship's weight is the highest weight for the current builder. This can be done with a simple sub query:
SELECT
builder, shipname, weight
FROM
ship
WHERE
weight = (SELECT MAX(i.weight) FROM ship i WHERE i.builder = ship.builder)
ORDER BY builder;