I have a problem solving this real scenario. I have two data tables:
- dfEntitiesCountries: a table of 3-letter entities vs their Routing Countries
- temp: a big table of shipments each with the following details: a. AWB: identifier of the shipment b. OriginCountry: full name of a shipment origin country c. Route: the entities thru which a shipment has moved separated by a hyphen
dfEntitiesCountries
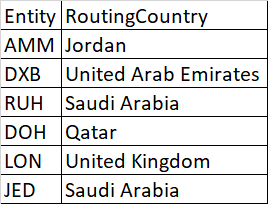
temp table
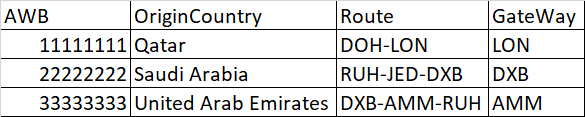
I need to figure out the Gateway of each shipment. Gateway is the entity in the Route with Routing Country that comes right after the OriginCountry of the shipment. This means that I need to exclude the first entities in route that correspond to the OriginCountry of the shipment, then take the entity in route whose RountingCountry is different from the OriginCountry.
I wrote the below code. The problem is that it works well if I use it as a standalone function (GetGW). But when I use it in the vapply to apply it on all shipments in temp table I face an error saying:
“Error in [.data.table(dfEntitiesCountries[RouteEntities, on = .(Entity = V1), :
i evaluates to a logical vector length 3 but there are 2 rows. Recycling of logical i is no longer allowed as it hides more bugs than is worth the rare convenience. Explicitly use rep(...,length=.N) if you really need to recycle.”
GetGW <- function(RouteEntities,ShptOrgCnt){
setDT(as.list(RouteEntities))
GW <-dfEntitiesCountries[RouteEntities,on=.(Entity=V1),nomatch=0][RoutingCountry!=ShptOrgCnt,.(Entity)][[1]][1]%>% as.character()
}
temp[,`:=`(GateWay=vapply(strsplit(Route,"-"),GetGW,"character",ShptOrgCnt=OriginCountry))]
Appreciate any thought to resolve this case using the same method or any other efficient method as I have around 2M shipments in the actual table.
CodePudding user response:
Not a full answer, but would highly recommend looking at tidyverse's stringr package which has a lot of tools that could help with this. Combine with dplyr::across() and/or dplyr::rowwise() to apply to your whole dataset.
CodePudding user response:
Step 1: identify the first abbreviation of each country:
dfEntitiesCountries[dfEntitiesCountries, Entity2 := first(i.Entity), on = .(RoutingCountry), by = .EACHI]
dfEntitiesCountries
# Entity RoutingCountry Entity2
# <char> <char> <char>
# 1: AMM J AMM
# 2: DXB UAE DXB
# 3: RUH SA JED
# 4: DOH Q DOH
# 5: LON UK LON
# 6: JED SA JED
Step 2: form a temp2 that calculates the gateway for each AWB:
temp2 <- copy(temp)[dfEntitiesCountries, Orig := i.Entity2, on = .(OriginCountry = RoutingCountry)
][, strsplit(Route, "-"), by = .(AWB, Orig)
][dfEntitiesCountries, Gateway := i.Entity2, on = .(V1 = Entity)
][Orig != Gateway,
][, .SD[1,], by = .(AWB)]
Step 3: bring this back into the original temp:
temp[temp2, Gateway2 := i.Gateway, on = .(AWB)]
temp
# AWB OriginCountry Route GateWay Gateway2
# <num> <char> <char> <char> <char>
# 1: 1111 Q DOH-LON LON LON
# 2: 2222 SA RUH-JED-DXB DXB DXB
# 3: 3333 UAE DXB-AMM-RUH AMM AMM
Data
dfEntitiesCountries <- setDT(structure(list(Entity = c("AMM", "DXB", "RUH", "DOH", "LON", "JED"), RoutingCountry = c("J", "UAE", "SA", "Q", "UK", "SA")), row.names = c(NA, -6L), class = c("data.table", "data.frame")))
temp <- setDT(structure(list(AWB = c(1111, 2222, 3333), OriginCountry = c("Q", "SA", "UAE"), Route = c("DOH-LON", "RUH-JED-DXB", "DXB-AMM-RUH"), GateWay = c("LON", "DXB", "AMM")), row.names = c(NA, -3L), class = c("data.table", "data.frame")))