I have a Spark dataframe like the one below:
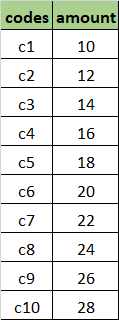
Also, another dataframe:

The output that I expect is below. I need two columns to be added conditionally to the original data dataframe where:
"offeramount1" = 75% of (amount)
"offeramount2" = 65% of (amount)
This offer is only to be given when the code is not in the "exclusioncode"
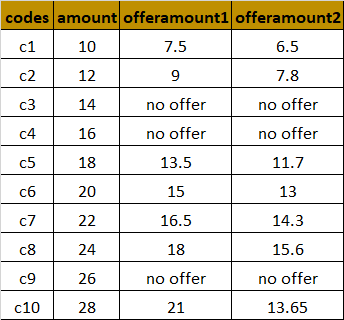
I am able to add the columns without any issues using withColumn, but I'm unable to compare the data frames properly.
CodePudding user response:
You could do two joins - 'leftanti' and 'right':
Input:
from pyspark.sql import functions as F
df1 = spark.createDataFrame([('c1', 10), ('c2', 12), ('c3', 14), ('c4', 16), ('c5', 18), ('c6', 20), ('c7', 22), ('c8', 24), ('c9', 26), ('c10', 28)], ['codes', 'amount'])
df2 = spark.createDataFrame([('c3',), ('c4',), ('c9',)], ['exclusioncode'])
Script:
df = (df1
.join(df2, df1.codes == df2.exclusioncode, 'leftanti')
.withColumn('offeramount1', F.round(F.col('amount') * .75, 1))
.withColumn('offeramount2', F.round(F.col('amount') * .65, 1))
.join(df1, ['codes', 'amount'], 'right')
)
df.show()
# ----- ------ ------------ ------------
# |codes|amount|offeramount1|offeramount2|
# ----- ------ ------------ ------------
# | c3| 14| null| null|
# | c1| 10| 7.5| 6.5|
# | c4| 16| null| null|
# | c5| 18| 13.5| 11.7|
# | c2| 12| 9.0| 7.8|
# | c6| 20| 15.0| 13.0|
# | c10| 28| 21.0| 18.2|
# | c8| 24| 18.0| 15.6|
# | c7| 22| 16.5| 14.3|
# | c9| 26| null| null|
# ----- ------ ------------ ------------
You cannot fill null values with "no offer", as columns in Spark contain only one data type. "no offer" would be a string while other values are numeric, hence two separate data types.
CodePudding user response:
You can use a left join and a when condition (I'll call amount_df the DataFrame with the amounts for each code, while exclusion_code_df the DataFrame with the codes to be excluded):
offer_df = (
amount_df
.join(exclusion_code_df, F.col('codes') == F.col('exclusioncode'), how='left')
.withColumn('offeramount1', F.when(F.col('exclusioncode').isNull(), 0.75 * F.col('amount')).otherwise('no offer'))
.withColumn('offeramount2', F.when(F.col('exclusioncode').isNull(), 0.65 * F.col('amount')).otherwise('no offer'))
.drop('exclusioncode')
)
offer_df is the following DataFrame:
----- ------ ------------ ------------------
|codes|amount|offeramount1|offeramount2 |
----- ------ ------------ ------------------
|c1 |10 |7.5 |6.5 |
|c10 |28 |21.0 |18.2 |
|c2 |12 |9.0 |7.800000000000001 |
|c3 |14 |no offer |no offer |
|c4 |16 |no offer |no offer |
|c5 |18 |13.5 |11.700000000000001|
|c6 |20 |15.0 |13.0 |
|c7 |22 |16.5 |14.3 |
|c8 |24 |18.0 |15.600000000000001|
|c9 |26 |no offer |no offer |
----- ------ ------------ ------------------