Below is my code.
import requests
import re
import pandas as pd
from bs4 import BeautifulSoup
r = requests.get("https://www.gutenberg.org/browse/scores/top")
soup = BeautifulSoup(r.content,"lxml")
List1 = soup.find_all('ol')
List1
newlist = []
for List in List1:
ulList = List.find_all('li')
extend_list = []
for li in ulList:
#extend_list = []
for link in li.find_all('a'):
a = link.get_text()
print(a)
my output is
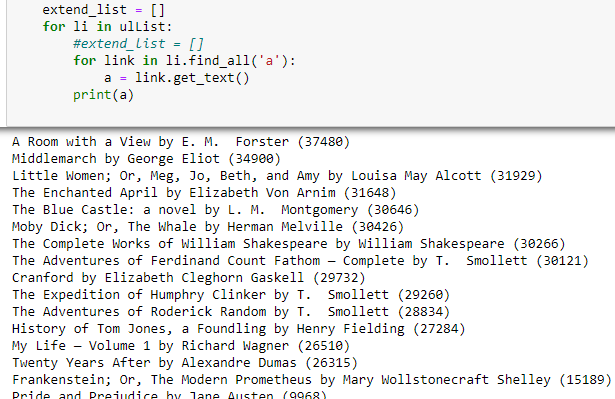
I want to convert the output into list of list
[['A Room with a View by E. M. Forster (37480)'], ['Middlemarch by George Eliot (34900)'],['Little Women; Or, Meg, Jo, Beth, and Amy by Louisa May Alcott (31929)']]Split the list into two parts
[["A Room with a View by E. M. Forster", "37480"], ["Middlemarch by George Eliot", "34900"],["Little Women; Or, Meg, Jo, Beth, and Amy by Louisa May Alcott", "31929"]]Load the data into data frame

CodePudding user response:
Simplify your code, while selecting your elements more specific:
for e in soup.select('ol a'):
data.append({
'Ebook':e.text.split('(')[0].strip(),
'Code':e.text.split('(')[-1].strip(')')
})
Example
import requests
import pandas as pd
from bs4 import BeautifulSoup
r = requests.get("https://www.gutenberg.org/browse/scores/top")
soup = BeautifulSoup(r.content,"lxml")
data = []
for e in soup.select('ol a'):
data.append({
'Ebook':e.text.split('(')[0].strip(),
'Code':e.text.split('(')[-1].strip(')')
})
pd.DataFrame(data)
Output
| Ebook | Code | |
|---|---|---|
| 0 | A Room with a View by E. M. Forster | 37480 |
| 1 | Middlemarch by George Eliot | 34900 |
| 2 | Little Women; Or, Meg, Jo, Beth, and Amy by Louisa May Alcott | 31929 |
| 3 | The Enchanted April by Elizabeth Von Arnim | 31648 |
| 4 | The Blue Castle: a novel by L. M. Montgomery | 30646 |
| 5 | Moby Dick; Or, The Whale by Herman Melville | 30426 |
| 6 | The Complete Works of William Shakespeare by William Shakespeare | 30266 |
...
CodePudding user response:
You can do it in one step with a short regex and str.extract:
df = (pd.Series([e.text for e in soup.select('ol a')])
.str.extract(r'(.*) \((\d )\)$')
.set_axis(['Ebooks', 'Code'], axis=1)
)
If you need the intermediate list of lists:
import re
L = [list(m.groups()) for e in soup.select('ol a')
if (m:=re.search(r'(.*) \((\d )\)$', e.text))]
df = pd.DataFrame(L, columns=['Ebooks', 'Code'])
output:
Ebooks Code
0 A Room with a View by E. M. Forster 37480
1 Middlemarch by George Eliot 34900
2 Little Women; Or, Meg, Jo, Beth, and Amy by Lo... 31929
3 The Enchanted April by Elizabeth Von Arnim 31648
4 The Blue Castle: a novel by L. M. Montgomery 30646
.. ... ...
395 Hapgood, Isabel Florence 12240
396 Mill, John Stuart 12223
397 Marlowe, Christopher 11760
398 Wharton, Edith 11728
399 Burnett, Frances Hodgson 11630
[400 rows x 2 columns]