I'm trying to divide the two following dfs--
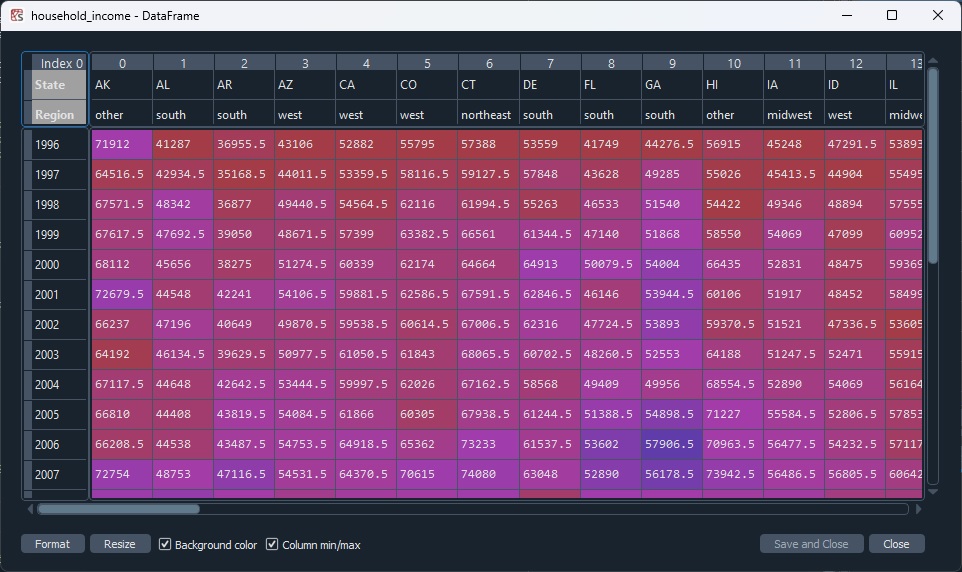
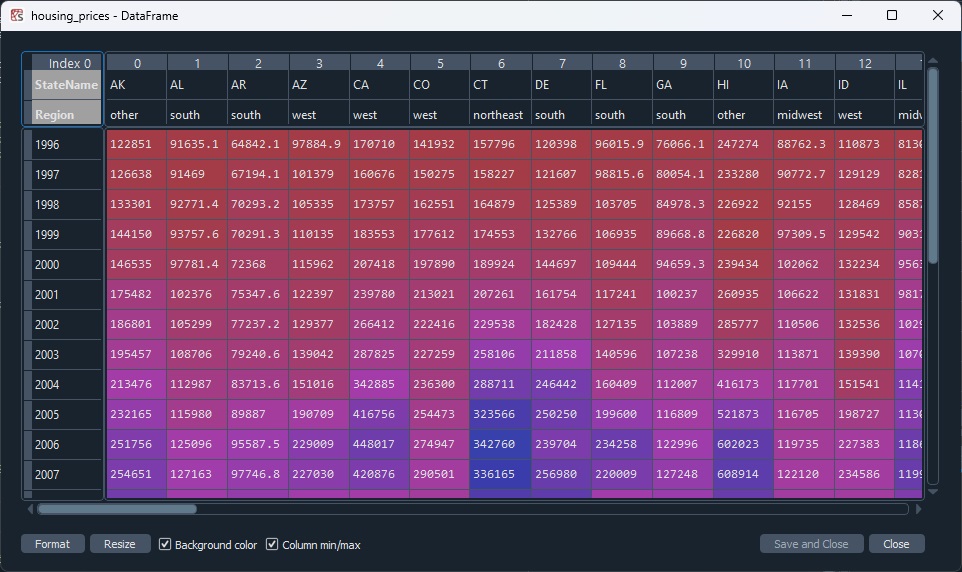
The are both size (26,50) and all data is Int64 type.
When I use the pandas divide function I get a (52,50) DF with all nans.
When I use the following--
blah = housing_prices.divide(household_income)
The output I get is a (52,50) dataframe with all nan values--
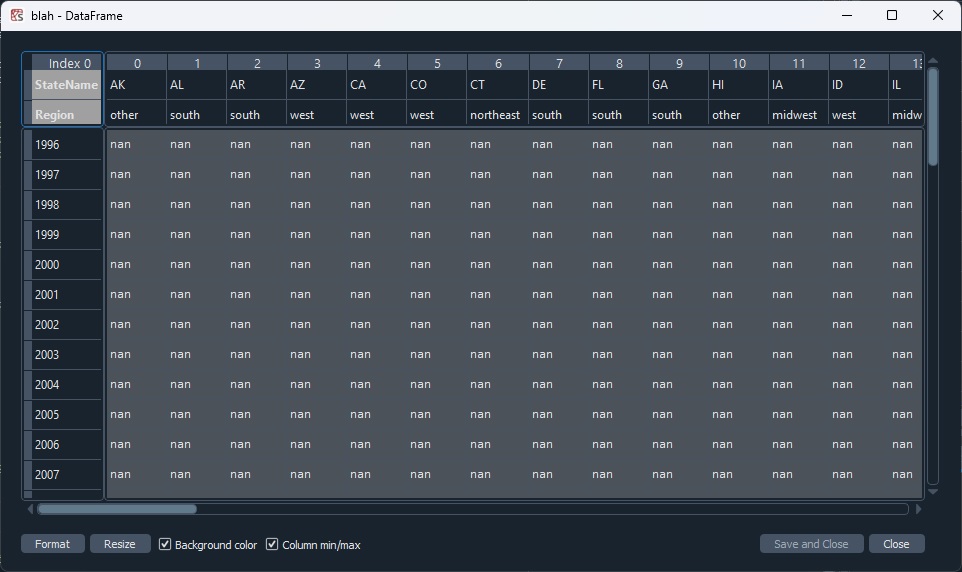
I tried specifying the axis parameter as both 'index' and 'columns', as well as changing the level parameters around but to no avail.
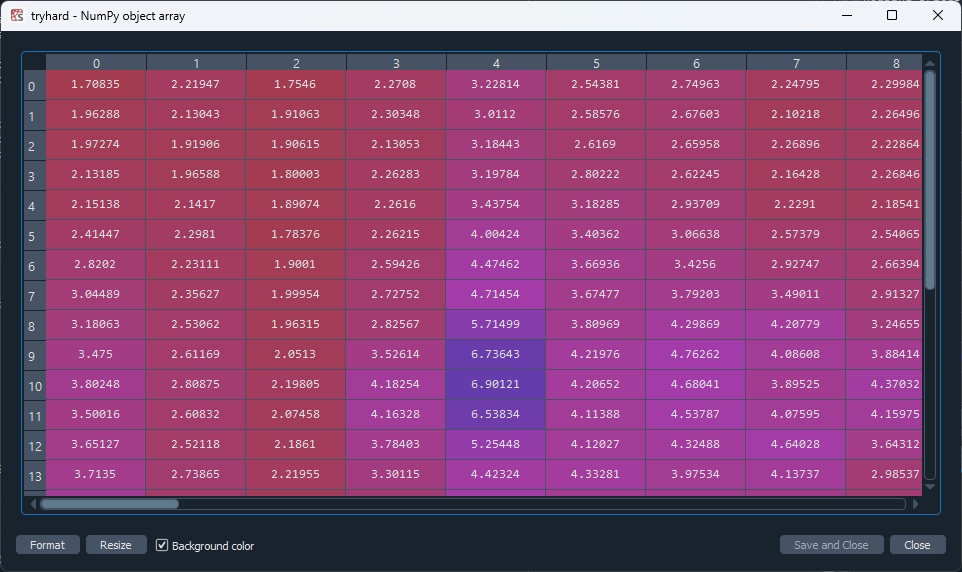
I can pull the values directly as an Array and divide those, but I would rather it just be a df so I can ensure order is held.
income = household_income.values
prices = housing_prices.values
tryhard = prices / income
Much appreciated if someone can tell me what I'm missing to get my dfs to divide nicely :)!!!
(this is my first ever posted question so feel free to give me feedback on additional information I should have included)
Update- Sample Data
There is probably an easier way to do this but I have attached example data and how to import it in so it's in a similar format as below!
household_income_sample.csv:
State,AK,AL,AR
Region,other,south,south
Year,,,
1996,71912,41287,36955.5
1997,64516.5,42934.5,35168.5
housing_prices_sample.csv:
StateName,AK,AL,AR
Region,other,south,south
Year,,,
1996,122851.0825,91635.08544,64842.1332
1997,126638.1935,91469.003,67194.06195
Read in csv's and put into similar format:
household_income_sample = pd.read_csv('household_income_sample.csv', index_col=0)
household_income_sample.columns = pd.MultiIndex.from_arrays([household_income_sample.columns, household_income_sample.iloc[0].values])
household_income_sample = household_income_sample.iloc[2:]
housing_prices_sample = pd.read_csv('housing_prices_sample.csv', index_col=0)
housing_prices_sample.columns = pd.MultiIndex.from_arrays([housing_prices_sample.columns, housing_prices_sample.iloc[0].values])
housing_prices_sample = housing_prices_sample.iloc[2:]
CodePudding user response:
The issue comes from your method of reading the CSV files.
You initially keep the subheaders as values, then craft a MultiIndex. This results in the dtype of your data being object.
Directly read the headers as MultiIndex:
household_income_sample = pd.read_csv('household_income_sample.csv', index_col=0, header=[0, 1])
housing_prices_sample = pd.read_csv('housing_prices_sample.csv', index_col=0, header=[0, 1])
housing_prices.divide(household_income)
Output:
StateName AK AL AR
Region other south south
Year
1996 1.708353 2.219466 1.754600
1997 1.962881 2.130431 1.910632