Any help in figuring this out would be appreciated. I would like a forumla to calculate the number of times a code number appears more than once AND where type is A.
A sample set of data looks like the following:
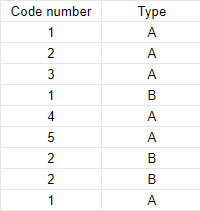
In this case the forumla should return 1 as there is one case of a repeated code number (1) where type is (A) - first row and last row in this case.
Would the forumla be any different if I also had a third column and wanted that to be a certain value as well? Again with the test data below I would want this to return 1 in the case that I wanted to measure the number of times any code number appeared more than once where type=A and subtype=C:
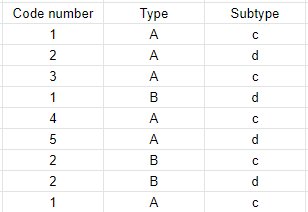 .
.
Ihave started with the following which identifies the number of unique combinations in columns A and B, but I can't seem to add any way to only return where a particular combination appears more than once:
=COUNTUNIQUE(IFERROR(FILTER(A2:A,B2:B="A"),""))
I have tried the following but it doesn't return correctly:
=COUNTUNIQUE(IFERROR(FILTER(A2:A,B2:B="A",COUNTIF(A2:A,A2:A)>1)))
Been trying to figure this one out for a while with no success. Thank you
CodePudding user response:
You can try this (TABLE = the range corresponding to your dataset, including the header row):
=query(query(transpose(query(transpose(TABLE),,9^9)),"select Col1,count(Col1) where Col1 contains 'A' group by Col1",1),"select Col2-1 where Col2>1 label Col2-1 ''")
What we are doing is to concatenate the Code number & type columns into one using the TRANSPOSE/QUERY/TRANSPOSE...9^9 hack, querying it again to make a temporary table of each group against its count for those groups which meet the criteria, then finally subtracting one from each group count and only returning an answer if there were groups with count>1 to begin with. You will get multiple results if multiple groups satisfy the count>1 criteria.
To add the subtype column to the formula as per the second question, change TABLE to suit, then change the inner QUERY to:
"select Col1,count(Col1) where Col1 contains 'A' and Col1 contains 'c' group by Col1"
Note that the if your 'real' type & subtype categories share characters then the where/contains approach in the QUERY will fail and a different approach will be needed.
CodePudding user response:
Assume that you place you data at A1:B10, what this function do is:
FILTER B1:B10 by type, which is "A" in this example, and return an array which is filtered A1:B10.
Use INDEX to extract only the 1st column, which is the code column of the filtered array, and name it 'DATA' with LAMBDA function.
Use BYROW to iterate 'DATA', and check each code with COUNTIF, if it counts more than one of this code in the filter result, return that code, else return "".
Use UNIQUE to get rid of duplicate results. (since we are looking for code which have more than 1 repeats, so the return array will sure have duplicates.)
Use query to get rid of the extry empty rows.
=QUERY(UNIQUE(
LAMBDA(DATA,
BYROW(DATA,LAMBDA(ROW,
IF(COUNTIF(DATA,ROW)>1,ROW,"")
))
)(INDEX(FILTER(A1:B10,B1:B10="A"),,1))
),"WHERE Col1 IS NOT NULL")
Just noticed that the INDEX function is not necessary, FLITER can directly returns A1:A10 according the compare results of B1:B10.
=QUERY(UNIQUE(
LAMBDA(DATA,
BYROW(DATA,LAMBDA(ROW,
IF(COUNTIF(DATA,ROW)>1,ROW,"")
))
)(FILTER(A1:A10,B1:B10="A"))
),"WHERE Col1 IS NOT NULL")