I have this large dataframe, illustrated below is for simplicity purposes.
pd.DataFrame(df.groupby(['Pclass', 'Sex'])['Age'].median())
Groupby results:
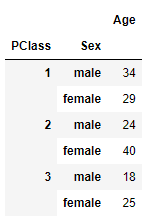
And it have this data that needs to be imputed
Missing Data:
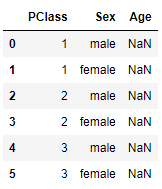
How can I impute these values based on the median of the grouped statistic
The result that I want is:
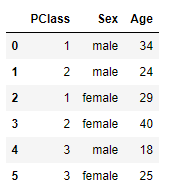
# You can use this for reference
import numpy as np
import pandas as pd
mldx_arrays = [np.array([1, 1,
2, 2,
3, 3]),
np.array(['male', 'female',
'male', 'female',
'male', 'female'])]
multiindex_df = pd.DataFrame(
[34,29,24,40,18,25], index=mldx_arrays,
columns=['Age'])
multiindex_df.index.names = ['PClass', 'Sex']
multiindex_df
d = {'PClass': [1, 1, 2, 2, 3, 3],
'Sex': ['male', 'female', 'male', 'female', 'male', 'female'],
'Age': [np.nan, np.nan, np.nan, np.nan, np.nan, np.nan]}
df = pd.DataFrame(data=d)
CodePudding user response:
If all values are missing remove Age column and use DataFrame.join:
df = df.drop('Age', axis=1).join(multiindex_df, on=['PClass','Sex'])
print (df)
PClass Sex Age
0 1 male 34
1 1 female 29
2 2 male 24
3 2 female 40
4 3 male 18
5 3 female 25
If need replace only missing values use DataFrame.join and replace missing values in original column:
df = df.join(multiindex_df, on=['PClass','Sex'], rsuffix='_')
df['Age'] = df['Age'].fillna(df.pop('Age_'))
print (df)
PClass Sex Age
0 1 male 34.0
1 1 female 29.0
2 2 male 24.0
3 2 female 40.0
4 3 male 18.0
5 3 female 25.0
If need replace missing values by median per groups use GroupBy.transform:
df['Age'] = df['Age'].fillna(df.groupby(['PClass', 'Sex'])['Age'].transform('median'))
CodePudding user response:
Given your example case you can simply assign the Series to the dataframe and re-define the column:
df['Age'] = base_df.groupby(['Pclass', 'Sex'])['Age'].median()
Otherwise you need to careful of positioning and in case it's not sorted you might want to use sort_index() or sort_values() first, depending on the case.