I'm working on an access query and kinda hit a dead end. I want to delete all duplicate rows in a table that have the same value in the columns Brand, SerialNr, Seats and LastRepair that have the value "2013" in the year column.
I'm trying to delete all rows that have duplicates in those columns and the year 2013 so there isnt a single one left. (Not just delete the duplicated so there is only one left but delete all instances so there is none left)
The original table looks like this:
| Brand | SerialNr | Seats | Color | LastRepair | Year |
|---|---|---|---|---|---|
| Ford | 145 | 4 | Blue | 01.01.2020 | 2010 |
| Ford | 145 | 4 | Red | 01.01.2020 | 2010 |
| Ford | 145 | 4 | Red | 01.01.2020 | 2013 |
| Ford | 145 | 4 | Green | 01.01.2020 | 2013 |
| Porsche | 146 | 2 | White | 01.01.2022 | 2013 |
| Ferrari | 146 | 2 | White | 01.01.2022 | 2013 |
| Volkswagen | 147 | 4 | Blue | 01.01.2021 | 2017 |
| Volkswagen | 147 | 4 | Red | 01.01.2021 | 2013 |
| Volkswagen | 147 | 4 | Orange | 01.01.2021 | 2013 |
And the outcome table should look like this:
| Brand | SerialNr | Seats | Color | LastRepair | Year |
|---|---|---|---|---|---|
| Ford | 145 | 4 | Blue | 01.01.2020 | 2010 |
| Ford | 145 | 4 | Red | 01.01.2020 | 2010 |
| Porsche | 146 | 2 | White | 01.01.2022 | 2013 |
| Ferrari | 146 | 2 | White | 01.01.2022 | 2013 |
| Volkswagen | 147 | 4 | Blue | 01.01.2021 | 2017 |
I tried doing it with this question but I need the rows deleted if they have a duplicated value in the those columns so there isnt a single one left who has the same year.
I also tried to do a "find duplicates" query and make an outter join but was unsuccesful so far achieving the desired outcome. I'm thankful for any help.
CodePudding user response:
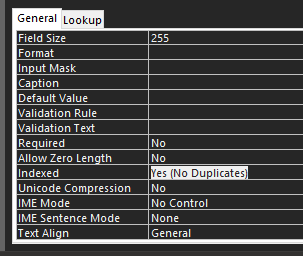
If your goal is to never have duplicate information in the "Brand" column, that can be accomplished in the table design itself. It's much more efficient to setup the table such that it limits what the user can input in certain circumstances. There's a couple ways you can do this. You can set the primary key to the Brand column, or change the "Indexed" property of that column to "Yes (No Duplicates)" If you are using an auto-number as the ID field and plan on relating a table by that ID, then the index is your best bet.
CodePudding user response:
You can use an EXISTS subquery to identify duplicated rows and delete them.
In the subquery, we just select based on the columns you want to identify duplicates by, then check if the count is greater than 1 (since Count is an aggregate, it's in the HAVING clause).
DELETE * FROM t AS t1
WHERE EXISTS(
SELECT 1
FROM t As t2
WHERE t1.Brand = t2.Brand AND t1.SerialNr = t2.SerialNr AND t1.Seats = t2.Seats AND t1.LastRepair = t2.LastRepair
HAVING Count(*) > 1
)
AND Year = 2013