I have a json object
sample_json ={
"workspaces": [
{
"wsid": "1",
"wsname": "firstworkspace",
"report":[{"reportname":"r1ws1"},{"reportname":"r2ws1"},{"reportname":"r1ws1"}]
},
{
"wsid": "2",
"wsname": "secondworkspace",
"report":[{"reportname":"r1ws2"},{"reportname":"r2ws2"},{"reportname":"r1ws2"}]
}
]}
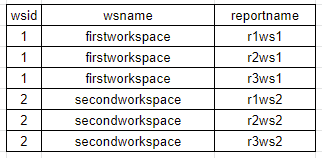
I want to flatten/normalize the json so that it looks like this :
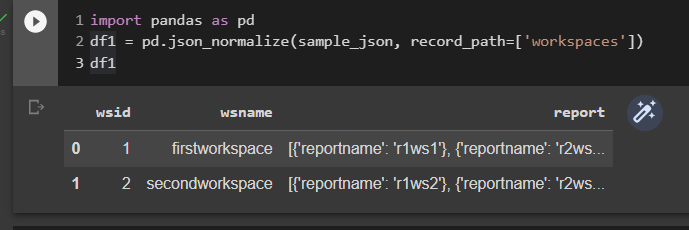
I can flatten each level using the pandas function "json_normalize" e.g Level 1
import pandas as pd
df1 = pd.json_normalize(sample_json, record_path=['workspaces'])
df1
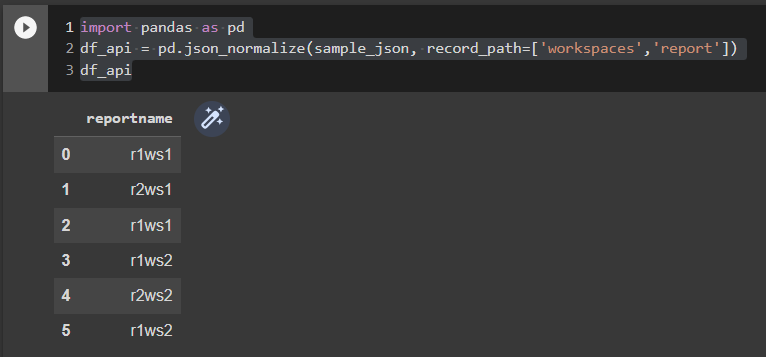
e.g Level 2
import pandas as pd
df_api = pd.json_normalize(sample_json, record_path=['workspaces','report'])
df_api
I have read quiet a few articles such as this one but I am struggling to understand how to include information from the two levels (workspaces and reports) in a single dataframe. Any advice or help would be appreciated. Copy to sample data in a google colab notebook is here
CodePudding user response:
So, just normalize this yourself.
df = pd.DataFrame(
[
{"wsid": ws['wsid'], "wsname": ws['wsname'], **rep}
for ws in sample_json["workspaces"] for rep in ws['report']
]
)
CodePudding user response:
The package jertl can be used for this.
In [1]: import jertl
In [2]: import pandas as pd
In [3]: sample_json = ... #removed for brevity
In [4]: pattern = '''
...: {
...: "workspaces": [*_,
...: {
...: "wsid": wsid,
...: "wsname": wsname,
...: "report": [*_, {"reportname": reportname}, *_]
...: },
...: *_]
...: }
...: '''
In [5]: df = pd.DataFrame(match_.bindings for match_ in jertl.match_all(pattern, sample_json))
In [6]: df
Out[6]:
wsid wsname reportname
0 1 firstworkspace r1ws1
1 1 firstworkspace r2ws1
2 1 firstworkspace r1ws1
3 2 secondworkspace r1ws2
4 2 secondworkspace r2ws2
5 2 secondworkspace r1ws2
pattern defines the structure to look for. It is intentionally JSON like.
wsid, wsname and reportname are variables.
The *_s are splatted anonymous variables which match any number of list items.