I am running the below spark SQL with the subquery.
val df = spark.sql("""select * from employeesTableTempview where dep_id in (select dep_id from departmentTableTempview)""")
df.count()
I also run the same with the help of dataframe functional way like below, Let's assume we read the employee table and department table as a dataframes and their names should be empDF and DepDF respectively,
val depidList = DepDF.map(x=>x(0).string).collect().toList()
val empdf2 = empDF.filter(col("dep_id").isin(depidList:_*))
empdf2.count
In these above two scenarios, which one gives better performance and why? Please help me to understand this scenarios in spark scala.
CodePudding user response:
I can give you classic answer: it depends :D
Lets take a look at first case. I prepared similar example:
import org.apache.spark.sql.functions._
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
val data = Seq(("test", "3"),("test", "3"), ("test2", "5"), ("test3", "7"), ("test55", "86"))
val data2 = Seq(("test", "3"),("test", "3"), ("test2", "5"), ("test3", "6"), ("test33", "76"))
val df1 = data.toDF("name", "dep_id")
val df2 = data2.toDF("name", "dep_id")
df1.createOrReplaceTempView("employeesTableTempview")
df2.createOrReplaceTempView("departmentTableTempview")
val result = spark.sql("select * from employeesTableTempview where dep_id in (select dep_id from departmentTableTempview)")
result.count
I am setting autoBroadcastJoinThreshold to -1 because i assume that your datasets are going to be bigger than default 10mb for this parameter
This Sql query generates this plan:
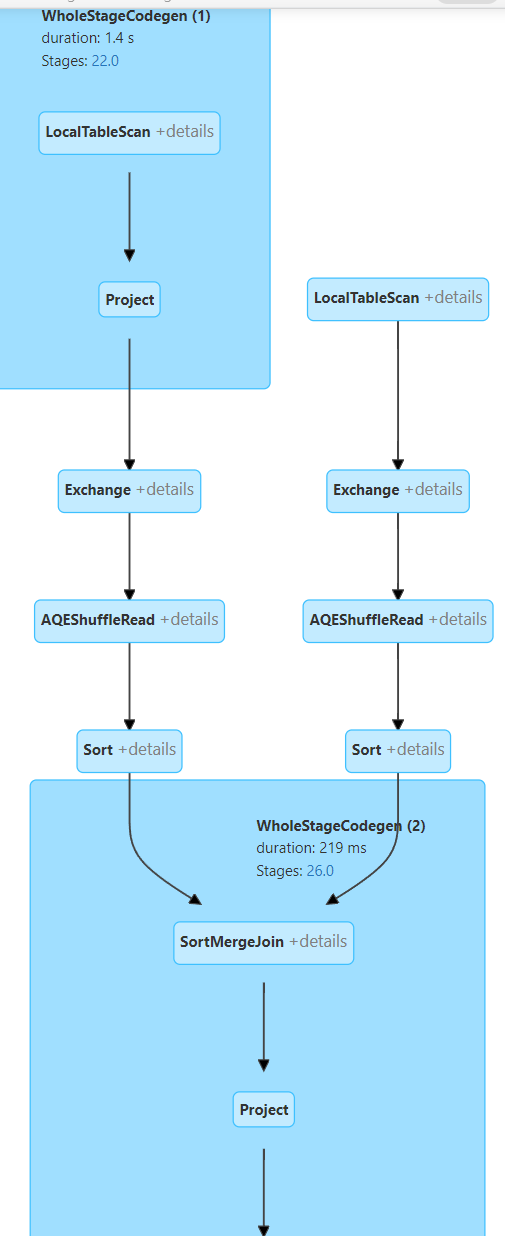
As you can see spark is performing a SMJ which will be a case most of the time for datasets bigger than 10mb. This requires data to be shuffled and then sorted so its quiet heavy operation
Now lets check option2 (first lines of codes are the same as previously):
val depidList = df1.map(x=>x.getString(1)).collect().toList
val empdf2 = df2.filter(col("dep_id").isin(depidList:_*))
empdf2.count
For this option plan is different. You dont have the join obviously but there are two separate sqls. First is for reading DepDF dataset and then collecting one column as a list. In second sql this list is used to filter the data in empDF dataset.
When DepDF is relatively small it should be fine, but if you need more generic solution you may stick to sub-query which is going to resolve to join. You can also use join directly on your dataframes with Spark df api