Summary
I would like to check that a cell contains the identical number of each letter from a-z and number from 0-9, as the cell next to it. The order does not matter, but the number of characters does. For example, if a cell contained "flat 1, 32 test road", and the cell next to it contained "32, flat 1, test road", it would match, as they both contain 3 t's, 2 a's, 1 l, etc.).
Example Table
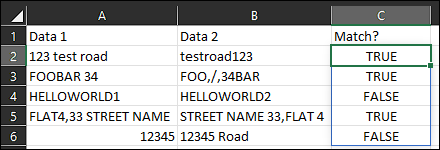
An example of the expected output is below, with the formula being populated in column C:
| Data 1 | Data 2 | Match? |
|---|---|---|
| 123 test road | testroad123 | MATCH |
| FOOBAR 34 | FOO,/,34BAR | MATCH |
| HELLOWORLD1 | HELLOWORLD2 | NO MATCH |
| FLAT4,33 STREET NAME | STREET NAME 33,FLAT 4 | MATCH |
| 12345 | 12345 Road | NO MATCH |
Working code
Currently, I have this working by first converting the contents of cell to lowercase, then individually checking each letter from a-z, and each number from 0-9 in an IF(AND) statement. It works, but looks horrible and undoubtedly is incredibly inefficient and resource intensive. The code is as follows:
=IF(AND(LEN(A1)-LEN(SUBSTITUTE(A1,"a",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"a","")),LEN(A1)-LEN(SUBSTITUTE(A1,"b",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"b","")),LEN(A1)-LEN(SUBSTITUTE(A1,"c",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"c","")),LEN(A1)-LEN(SUBSTITUTE(A1,"d",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"d","")),LEN(A1)-LEN(SUBSTITUTE(A1,"e",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"e","")),LEN(A1)-LEN(SUBSTITUTE(A1,"f",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"f","")),LEN(A1)-LEN(SUBSTITUTE(A1,"g",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"g","")),LEN(A1)-LEN(SUBSTITUTE(A1,"h",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"h","")),LEN(A1)-LEN(SUBSTITUTE(A1,"i",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"i","")),LEN(A1)-LEN(SUBSTITUTE(A1,"j",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"j","")),LEN(A1)-LEN(SUBSTITUTE(A1,"k",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"k","")),LEN(A1)-LEN(SUBSTITUTE(A1,"l",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"l","")),LEN(A1)-LEN(SUBSTITUTE(A1,"m",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"m","")),LEN(A1)-LEN(SUBSTITUTE(A1,"n",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"n","")),LEN(A1)-LEN(SUBSTITUTE(A1,"o",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"o","")),LEN(A1)-LEN(SUBSTITUTE(A1,"p",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"p","")),LEN(A1)-LEN(SUBSTITUTE(A1,"q",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"q","")),LEN(A1)-LEN(SUBSTITUTE(A1,"r",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"r","")),LEN(A1)-LEN(SUBSTITUTE(A1,"s",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"s","")),LEN(A1)-LEN(SUBSTITUTE(A1,"t",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"t","")),LEN(A1)-LEN(SUBSTITUTE(A1,"u",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"u","")),LEN(A1)-LEN(SUBSTITUTE(A1,"v",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"v","")),LEN(A1)-LEN(SUBSTITUTE(A1,"w",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"w","")),LEN(A1)-LEN(SUBSTITUTE(A1,"x",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"x","")),LEN(A1)-LEN(SUBSTITUTE(A1,"y",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"y","")),LEN(A1)-LEN(SUBSTITUTE(A1,"z",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"z","")),LEN(A1)-LEN(SUBSTITUTE(A1,"0",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"0","")),LEN(A1)-LEN(SUBSTITUTE(A1,"1",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"1","")),LEN(A1)-LEN(SUBSTITUTE(A1,"2",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"2","")),LEN(A1)-LEN(SUBSTITUTE(A1,"3",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"3","")),LEN(A1)-LEN(SUBSTITUTE(A1,"4",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"4","")),LEN(A1)-LEN(SUBSTITUTE(A1,"5",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"5","")),LEN(A1)-LEN(SUBSTITUTE(A1,"6",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"6","")),LEN(A1)-LEN(SUBSTITUTE(A1,"7",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"7","")),LEN(A1)-LEN(SUBSTITUTE(A1,"8",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"8","")),LEN(A1)-LEN(SUBSTITUTE(A1,"9",""))=LEN(B1)-LEN(SUBSTITUTE(B1,"9",""))),TRUE,FALSE)
As you can see, it's an eyesore. It works, but I will need to apply this to at least 100,000 rows of data, and I believe it will be too intensive to work reliably. The current solution is to go through each letter and make sure the count of them matches, and return TRUE if they all do.
Conclusion
I have a working solution that gives an example of what is required, but it's clunky and unreliable. I'm hoping there's a better way to utilise Excel in order to complete this task more efficiently. Thanks in advance for your time!
I am using MSO 365, Excel version 2202
CodePudding user response:
Alternative using LEN:
=AND(MMULT(LEN(A2:B2)-LEN(SUBSTITUTE(UPPER(A2:B2),MID("0123456789ABCDEFGHIJKLMNOPQRSTUVXYZ",SEQUENCE(36),1),"")),{-1;1})=0)
and copied down.
CodePudding user response:
Very nice question to work on. Here is one option that will spill results:
Formula in C2:
=BYROW(A2:B6,LAMBDA(x,COUNTA(UNIQUE(MAP(x,LAMBDA(a,CONCAT(LET(b,MID(a,SEQUENCE(LEN(a)),1),c,CODE(UPPER(b)),SORT(IFERROR(--b,IF((c>64)*(c<91),b,""))))))),1))))=1
In short:
BYROW()- Loop over each row in the dataset;MAP()- Each iteration of the above loop will pass both values through this function to split each element in characters, check if these are numbers, if not then check against the ASCIICODE()table, if neither return empty string.SORT()these characters andCONCAT()the result back together;COUNTA(UNIQUE())- Combination to test if the above iteration returned two of the same values (case insensitive).
CodePudding user response:
Nice answer from @JvdV.
I decided to write a lambda, CharFreq, to split the strings into characters and used Frequency to generate the frequencies of the characters and numbers. My lambda looked like this in the Advanced Formula Environment:
=LAMBDA(string,
LET(
codes, SEARCH(
MID(
string,
SEQUENCE(
LEN(
string
)
),
1
),
"0123456789abcdefghijklmnopqrstuvxyz"
),
fcodes, FILTER(
codes,
ISNUMBER(codes)
),
freq, FREQUENCY(
fcodes,
SEQUENCE(36)
),
freq
)
)
Then I could just compare the frequencies to identify any discrepancies:
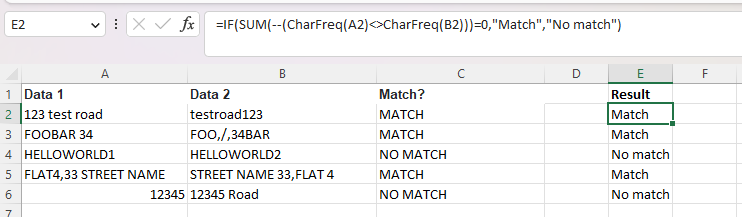
=IF(SUM(--(CharFreq(A2)<>CharFreq(B2)))=0,"Match","No match")
Note
This could give the wrong result if a wildcard character like "*" or "?" occurred in one of the strings - could be fixed either by using find with lower instead of search, or by substituting out those characters.