For example, if there is a table named paper, I execute sql with [ select paper.user_id, paper.name, paper.score from paper where user_id in (201,205,209……) ]
I observed that when this statement is executed, index will only be used when the number of "in" is less than a certain number. and the certain number is dynamic. For example,when the total number of rows in the table is 4000 and cardinality is 3939, the number of "in" must be less than 790,MySQL will execute index query. (View MySQL explain. If <790, type=range; if >790, type=all) when the total number of rows in the table is 1300000 and cardinality is 1199166, the number of "in" must be less than 8500,MySQL will execute index query.
The result of this experiment is very strange to me.
I imagined that if I implemented this "in" query, I would first find in (max) and in (min), and then find the page where in (max) and in (min) are located,Then exclude the pages before in (min) and the pages after in (max). This is definitely faster than performing a full table scan.
Then, my test data can be summarized as follows: Data in the table 1 to 1300000 Data of "in" 900000 to 920000
My question is, in a table with 1300000 rows of data, why does MySQL think that when the number of "in" is more than 8500, it does not need to execute index queries?
mysql version 5.7.20
In fact, this magic number is 8452. When the total number of rows in my table is 600000, it is 8452. When the total number of rows is 1300000, it is still 8452. Following is my test screenshot
When the number of in is 8452, this query only takes 0.099s.
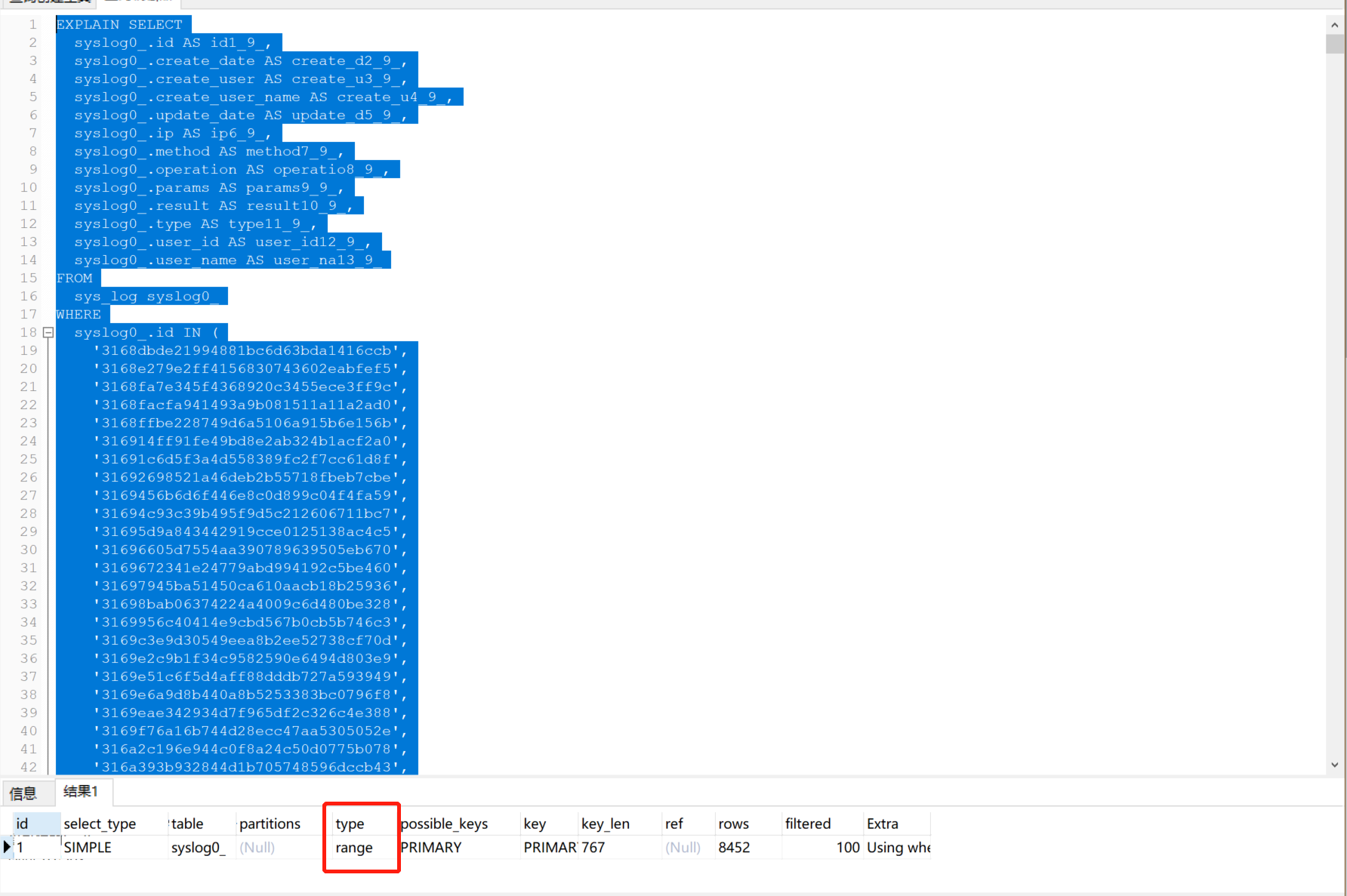
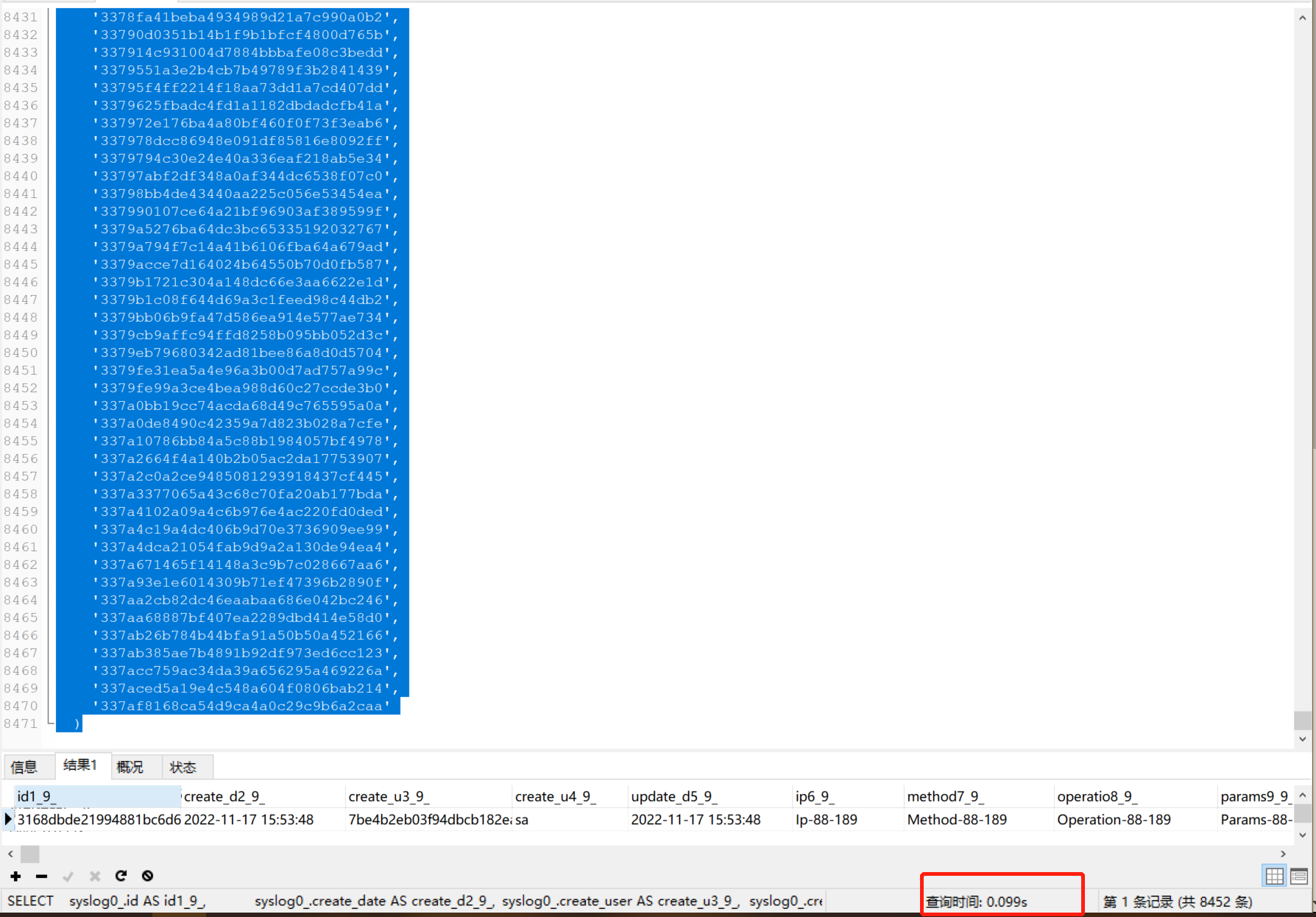 Then view the execution plan. range query.
Then view the execution plan. range query.
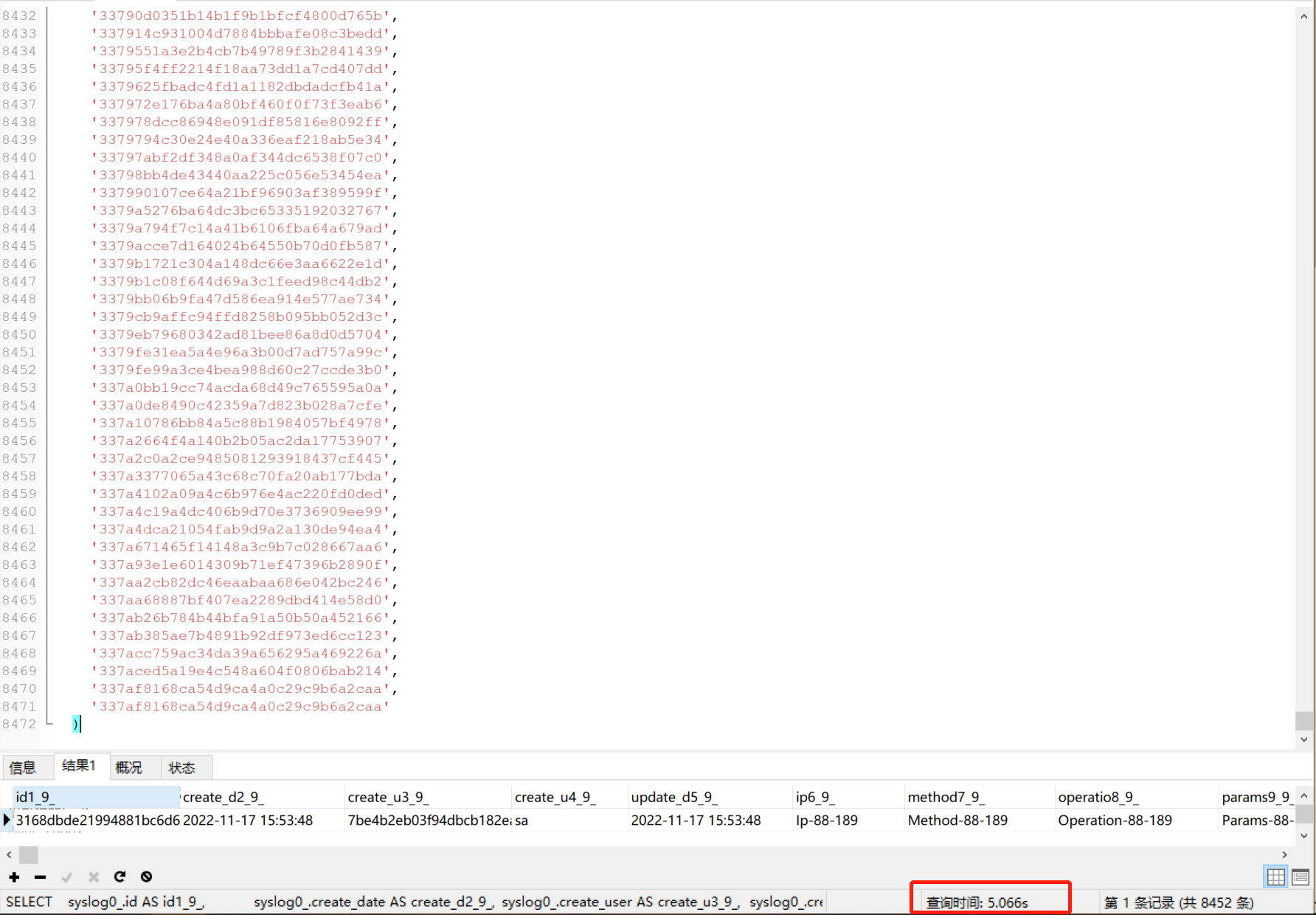
If I increase the number of in from 8452 to 8453, this query will take 5.066s, even if I only add a duplicate element.
Then view the execution plan. type all.
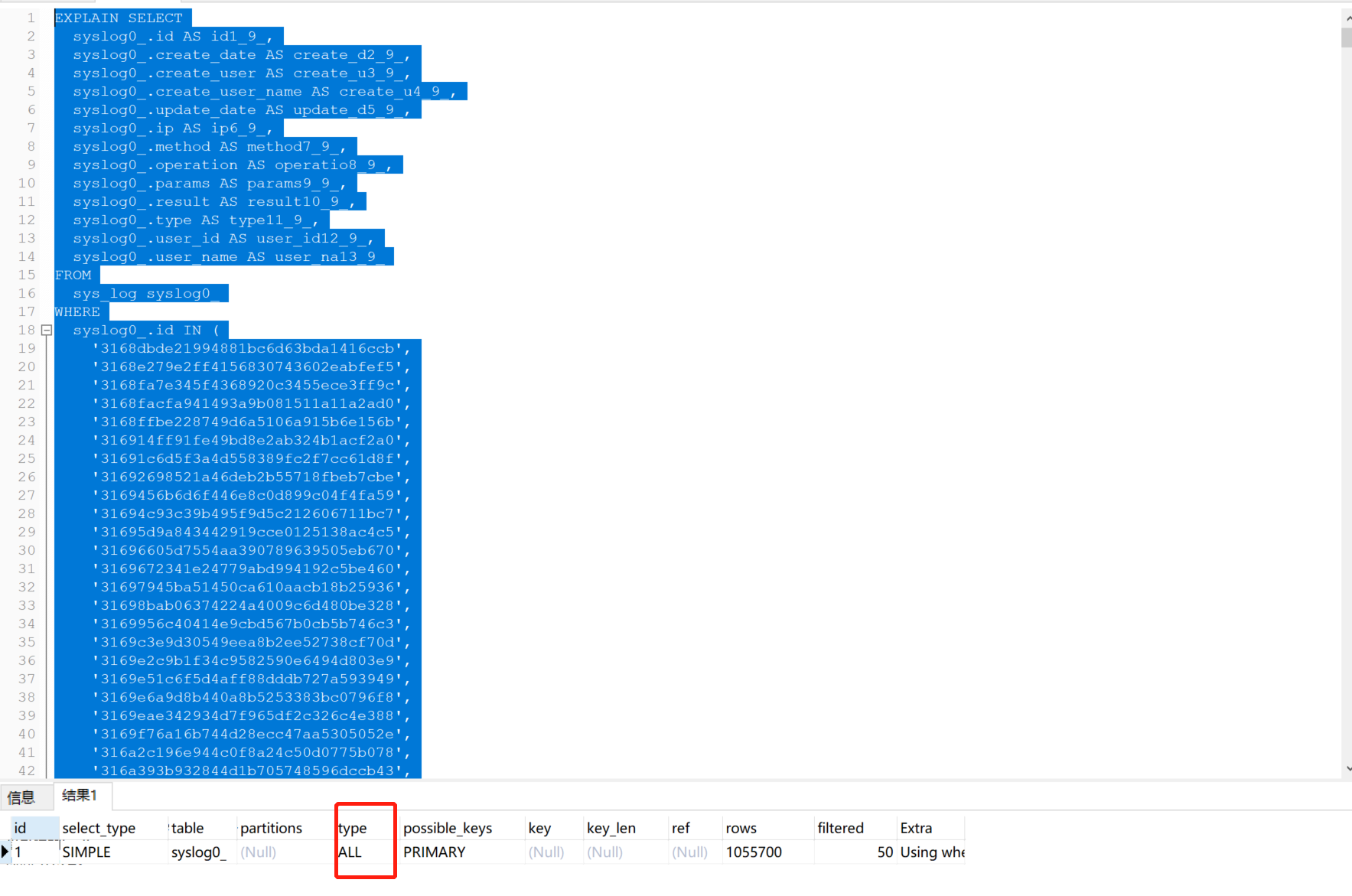
This is really strange. It means that if I execute the query with "8452 in" first, and then execute the remaining query, the total time is much faster than that of directly executing the query with "8453 in".
who can debug MySQL source code to see what happens in this process?
thanks very much.
CodePudding user response:
Great question and nice find!
The query planner/optimizer has to decide if it's going seek the pages it needs to read or it's going to start reading many more and scan for the ones it needs. The seek strategy is more memory and especially cpu intensive while the scan probably is significantly more expensive in terms of I/O.
The bigger a table the less attractive the seek strategy becomes. For a large table a bigger part of the nonclustered index used for the seek needs to come from disk, memory pressure rises and the potential for sequential reads shrinks the longer the seek takes. Therefore the threshold for the rows/results ratio to which a seek is considered lowers as the table size rises.
If this is a problem there're a few things you could try to tune. But when this is a problem for you in production it might be the right time to consider a server upgrade, optimizing the queries and software involved or simply adjust expectations.
- 'Harden' or (re)enforce the query plans you prefer
- Tweak the engine (when this is a problem that affects most tables server/database settings maybe can be optimized)
- Optimize nonclustered indexes
- Provide query hints
- Alter tables and datatypes
CodePudding user response:
It is usually folly go do a query in 2 steps. That framework seems to be fetching ids in one step, then fetching the real stuff in a second step.
If the two queries are combined into a single on (with a JOIN), the Optimizer is mostly forced to do the random lookups.
"Range" is perhaps always the "type" for IN lookups. Don't read anything into it. Whether IN looks at min and max to try to minimize disk hits -- I would expect this to be a 'recent' optimization. (I have not it in the Changelogs.)
Are those UUIDs with the dashes removed? They do not scale well to huge tables.
"Cardinality" is just an estimate. ANALYZE TABLE forces the recomputation of such stats. See if that changes the boundary, etc.