I have this txt file sentences.txt that contains texts below
a01-000u-s00-00 0 ok 154 19 408 746 1661 89 A|MOVE|to|stop|Mr.|Gaitskell|from
a01-000u-s00-01 0 ok 156 19 395 932 1850 105 nominating|any|more|Labour|life|Peers
which contains 10 columns I want to use the panda's data frame to extract only the file name (at column 0) and corresponding text (column 10) without the (|) character I wrote this code
def load() -> pd.DataFrame:
df = pd.read_csv('sentences.txt',sep=' ', header=None)
data = []
with open('sentences.txt') as infile:
for line in infile:
file_name, _, _, _, _, _, _, _, _, text = line.strip().split(' ')
data.append((file_name, cl_txt(text)))
df = pd.DataFrame(data, columns=['file_name', 'text'])
df.rename(columns={0: 'file_name', 9: 'text'}, inplace=True)
df['file_name'] = df['file_name'].apply(lambda x: x '.jpg')
df = df[['file_name', 'text']]
return df
def cl_txt(input_text: str) -> str:
text = input_text.replace(' ', '-')
text = text.replace('|', ' ')
return text
load()
the error I got
ParserError: Error tokenizing data. C error: Expected 10 fields in line 4, saw 11
where my expected process.txt file results should look like below without \n
a01-000u-s00-00 A MOVE to stop Mr. Gaitskell from
a01-000u-s00-01 nominating any more Labour life Peers
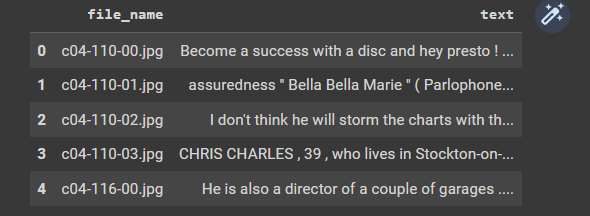
CodePudding user response:
IIUC, you just need 