I have two tables where TableA has latest data and TableB has some old data. I want to update TableB's data if it matches id with TableA and if doesn't match insert new row in TableB.
I got a solution from stackOverflow
begin tran
if exists (select * from t with (updlock,serializable) where pk = @id)
begin
update t set hitCount = hitCount 1
where pk = @id
end
else
begin
insert t (pk, hitCount)
values (@id, 1)
end
commit tran
But it seems I need to pass @id each time, may be I am not getting it in the correct way. I have hundreds of row to update/insert from tableA.
CodePudding user response:
Think relationally.
SQL Server always operates sets. A single row is just a set of 1 row.
Here is a simple example of two step update - insert operations
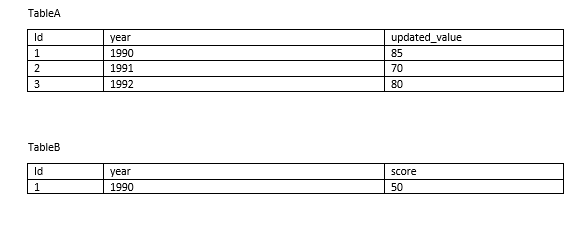
create table #tableA(id int, [year] int, updated_value int)
insert #tableA(id,[year],updated_value)
values
(1,1990,85),
(2,1991,70),
(3,1992,80)
create table #tableB(id int, [year] int, score int)
insert #tableB(id,[year],score)
values
(1,1990,50),
(4,1995,20)
update #tableA set
updated_value=b.score
from #tableA a
inner join #tableB b on a.id=b.id --inner is important
insert #tableA(id,[year],updated_value)
select b.id,b.[year],b.score
from #tableB b
left join #tableA a on a.id=b.id --left is important
where a.id is null -- and this line too
select * from #tableA
If you wish you can combine update and insert in a single merge operation.
merge #tableA as tgt
using #tableB as src
on src.id=tgt.id
when matched then
update set updated_value=src.score
when not matched then
insert(id,[year],updated_value)
values(id,[year],score)
; -- semicoloumn is required
select * from #tableA